
NVIDIA GPU Operator with OpenShift 4.3 on Red Hat OpenStack Platform 13
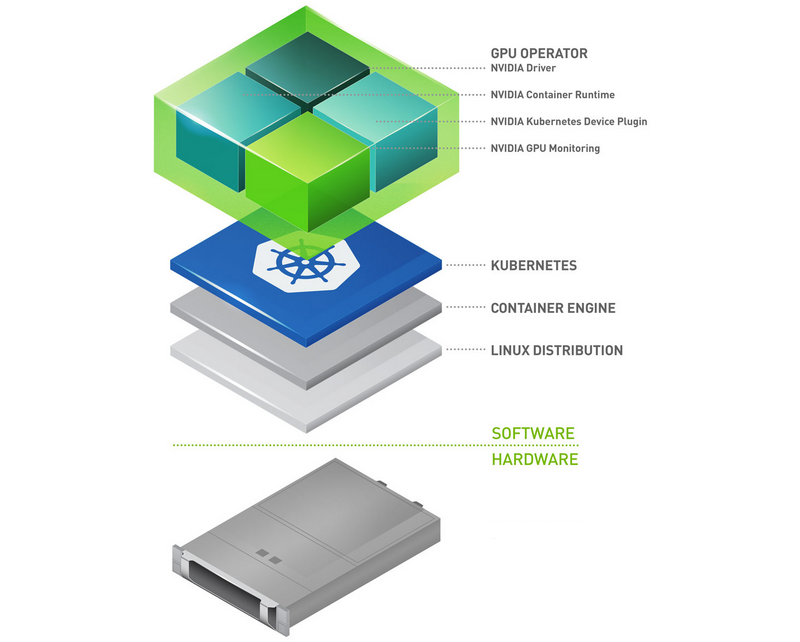
The NVIDIA GPU Operator has been available as a Beta since 2020, Jan 27, it’s a technical preview release: https://github.com/NVIDIA/gpu-operator/release
The GPU Operator manages NVIDIA GPU resources in an OpenShift cluster and automates tasks related to bootstrapping GPU nodes. Since the GPU is a special resource in the cluster, it requires a few components to be installed before application workloads can be deployed onto the GPU, these components include:
- the NVIDIA drivers (to enable CUDA)
- Kubernetes device plugin
- container runtime
- automatic node labelling
- monitoring

If you’re interested in following the NVIDIA GPU Operator upstream developments, I encourage you to follow this repository: https://github.com/NVIDIA/gpu-operator
Note: This blog post shows how to deploy GPU-enabled nodes running Red Hat Enterprise Linux CoreOS. With Red Hat OpenShift Container Platform 4, GPUs with OpenShift are supported in Red Hat Enterprise Linux 7 nodes only. This process using the NVIDIA GPU Operator is not yet supported.
We will apply this NVIDIA procedure: https://nvidia.github.io/gpu-operator/
Summary:
- OpenStack lab environment
- Prepare the OpenShift installer
- Deployment of OpenShift
- Check the OpenShift deployment
- Connect to the console
- Adding a GPU worker node
- Entitled builds
- Deploy the Node Feature Discovery Operator
- Deploy GPU Operator
- Test TensorFlow Notebook GPU
- Test nvidia-smi pod
- TensorFlow benchmarks with GPU
- TensorFlow benchmarks with CPU
- Configuring an HTPasswd identity provider
- MachineSet CPU worker scaling
- Product documentation
We will use the openshift-installer binary to spawn the OpenShift cluster on OpenStack.
The openshift-installer binary is directly consuming the OpenStack API.
At the end of the installation, we will have one OpenShift cluster running on seven OpenStack Virtual Machines:
- 3 x OpenShift masters VMs
- 3 x OpenShift workers for CPU workloads VMs
- 1 x OpenShift worker for GPU workload VM
You can run the same process with other IaaS platforms like AWS or Azure.
The OpenShift 4.3 installer can fully automate the installation on OpenStack:
- Network configuration (networks, subnets, trunks, load balancers)
- VM creation
- Storage configuration
- OpenShift setup
- Routing
The OpenStack Virtual Machine used as a GPU worker is using PCI passthrough to a NVIDIA Tesla V100 GPU board.
The OpenShift 4.3.1 cluster will use two Kubernetes Operators to setup the GPU configuration:
- Node Feature Discovery for Kubernetes (NFD) to label the GPU nodes
- NVIDIA GPU Operator for Kubernetes to enable the NVIDIA driver stack on the GPU worker node
OpenStack lab environment
We are using an already deployed Red Hat OpenStack Platform 13z8:
[stack@perflab-director ~]$ cat /etc/rhosp-release
Red Hat OpenStack Platform release 13.0.8 (Queens)
The compute nodes have two NVIDIA Tesla v100 with 16GB of GPU Memory:

List the PCI device IDs on one OpenStack compute node (two V100 boards plugged):
[heat-admin@overcloud-compute-0 ~]$ lspci -nn | grep -i nvidia
3b:00.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] [10de:1db4] (rev a1)
d8:00.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] [10de:1db4] (rev a1)
Create a flavor for the master and worker nodes:
[stack@perflab-director ~]$ source ~/overcloudrc
(overcloud) [stack@perflab-director ~]$ openstack flavor create --ram 1024 --disk 200 --vcpus 2 m1.xlarge
Add swiftoperator role to admin:
(overcloud) [stack@perflab-director ~]$ openstack role add --user admin --project admin swiftoperator
Set a temporary URL property:
(overcloud) [stack@perflab-director ~]$ openstack object store account set --property Temp-URL-Key=superkey
Prepare the OpenShift installer
The deployment process will run in multiple steps, to get the OpenShift installer go to:
http://try.openshift.com/
 and click on “GET STARTED”
and click on “GET STARTED”
Click on “Run on Red Hat OpenStack”

Now you are here and you can get all the resources: https://cloud.redhat.com/openshift/install/openstack/installer-provisioned
You can copy into your clipboard the pull secret string:

Official documentation: https://docs.openshift.com/container-platform/latest/installing/installing_openstack/installing-openstack-installer-custom.html
https://mirror.openshift.com/pub/openshift-v4/clients/ocp/latest/
Download the OpenShift Client and installer:
[stack@perflab-director ~]$ cd /usr/local/bin
[stack@perflab-director bin]$ sudo wget https://mirror.openshift.com/pub/openshift-v4/clients/ocp/latest/openshift-client-linux-4.3.1.tar.gz
[stack@perflab-director bin]$ sudo wget https://mirror.openshift.com/pub/openshift-v4/clients/ocp/latest/openshift-install-linux-4.3.1.tar.gz
[stack@perflab-director bin]$ ls -lah openshift-*
-rw-r--r-- 1 root root 26M Feb 3 18:11 openshift-client-linux-4.3.1.tar.gz
-rw-r--r-- 1 root root 79M Feb 3 18:04 openshift-install-linux-4.3.1.tar.gz
Untar and clean:
[stack@perflab-director bin]$ sudo tar xvzf openshift-client-linux-4.3.1.tar.gz
README.md
oc
kubectl
[stack@perflab-director bin]$ sudo tar xvzf openshift-install-linux-4.3.1.tar.gz
README.md
openshift-install
[stack@perflab-director bin]$ sudo /bin/rm README.md openshift-client-linux-4.3.1.tar.gz openshift-install-linux-4.3.1.tar.gz
Check your path and the version available:
[stack@perflab-director ~]$ openshift-install version
openshift-install v4.3.1
built from commit 2055609f95b19322ee6cfdd0bea73399297c4a3e
release image quay.io/openshift-release-dev/ocp-release@sha256:ea7ac3ad42169b39fce07e5e53403a028644810bee9a212e7456074894df40f3
[stack@perflab-director ~]$ oc version
Client Version: 4.3.1
Verify the name and ID of the OpenStack ‘External’ network:
[stack@perflab-director ~]$ source overcloudrc
(overcloud) [stack@perflab-director ~]$ openstack network list --long -c ID -c Name -c "Router Type"
+--------------------------------------+-------------+-------------+
| ID | Name | Router Type |
+--------------------------------------+-------------+-------------+
| 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | external | External |
| 4b4ddbd1-4b1c-491a-8160-36c77c559b13 | lb-mgmt-net | Internal |
+--------------------------------------+-------------+-------------+
Disable OpenStack quotas (not mandatory, but more simple for this lab):
(overcloud) [stack@perflab-director openshift]$ openstack quota set --secgroups -1 --secgroup-rules -1 --cores -1 --ram -1 --gigabytes -1 admin
(overcloud) [stack@perflab-director openshift]$ openstack quota show admin
+----------------------+----------------------------------+
| Field | Value |
+----------------------+----------------------------------+
| backup-gigabytes | 1000 |
| backups | 10 |
| cores | -1 |
| fixed-ips | -1 |
| floating-ips | 50 |
| gigabytes | -1 |
| gigabytes_tripleo | -1 |
| groups | 10 |
| health_monitors | None |
| injected-file-size | 10240 |
| injected-files | 5 |
| injected-path-size | 255 |
| instances | 10 |
| key-pairs | 100 |
| l7_policies | None |
| listeners | None |
| load_balancers | None |
| location | None |
| name | None |
| networks | 100 |
| per-volume-gigabytes | -1 |
| pools | None |
| ports | 500 |
| project | d88919769d1943b997338a89bdd991da |
| project_name | admin |
| properties | 128 |
| ram | -1 |
| rbac_policies | 10 |
| routers | 10 |
| secgroup-rules | -1 |
| secgroups | -1 |
| server-group-members | 10 |
| server-groups | 10 |
| snapshots | 10 |
| snapshots_tripleo | -1 |
| subnet_pools | -1 |
| subnets | 100 |
| volumes | 10 |
| volumes_tripleo | -1 |
+----------------------+----------------------------------+
Create an OpenStack flavor with 32GB of RAM and 4 vCPUS:
(overcloud) [stack@perflab-director openshift]$ openstack flavor create --ram 32768 --disk 200 --vcpus 4 m1.large
+----------------------------+--------------------------------------+
| Field | Value |
+----------------------------+--------------------------------------+
| OS-FLV-DISABLED:disabled | False |
| OS-FLV-EXT-DATA:ephemeral | 0 |
| disk | 200 |
| id | 2a90dead-ea97-434e-9bc8-8560cc0b88e4 |
| name | m1.large |
| os-flavor-access:is_public | True |
| properties | |
| ram | 32768 |
| rxtx_factor | 1.0 |
| swap | |
| vcpus | 4 |
+----------------------------+--------------------------------------+
Prepare OpenShift cloud.yaml configuration, first take you overcloud password:
[stack@perflab-director ~]$ cat ~/overcloudrc | grep OS_PASSWORD
export OS_PASSWORD=XXXXXXXXX
Download your clouds.yaml file in OpenStack Horizon, “Project” > “API Access” > “OpenStack clouds.yaml File”.
Prepare cloud.yaml configuration, add the password and rename “openstack” by “shiftstack”:
[stack@perflab-director openshift]$ mkdir -p ~/.config/openstack/
[stack@perflab-director ~]$ cat << EOF > ~/.config/openstack/clouds.yaml
# This is a clouds.yaml file, which can be used by OpenStack tools as a source
# of configuration on how to connect to a cloud. If this is your only cloud,
# just put this file in ~/.config/openstack/clouds.yaml and tools like
# python-openstackclient will just work with no further config. (You will need
# to add your password to the auth section)
# If you have more than one cloud account, add the cloud entry to the clouds
# section of your existing file and you can refer to them by name with
# OS_CLOUD=openstack or --os-cloud=openstack
clouds:
openstack:
auth:
auth_url: http://192.168.168.53:5000/v3
username: "admin"
password: XXXXXXXXXXXXXX
project_id: XXXXXXXXXXXXXX
project_name: "admin"
user_domain_name: "Default"
region_name: "regionOne"
interface: "public"
identity_api_version: 3
EOF
Setup the /etc/hosts file with the Floating IP:
echo -e "192.168.168.30 api.perflab.lan.redhat.com" | sudo tee -a /etc/hosts
Create an OpenShift account and download your OpenShift Pull secret key by clicking on “Copy Pull Secret” here, you will have to paste this content with the command"openshift-install create install-config":
https://cloud.redhat.com/openshift/install/openstack/installer-provisioned
Check the install-config.yaml prepared and update you “externalDNS” parameter:
(overcloud) [stack@perflab-director ~]$ openshift-install create install-config --dir='/home/stack/openshift'
? SSH Public Key /home/stack/.ssh/id_rsa_lambda.pub
? Platform openstack
? Cloud openstack
? ExternalNetwork external
? APIFloatingIPAddress 192.168.168.30
? FlavorName m1.large
? Base Domain lan.redhat.com
? Cluster Name perflab
? Pull Secret [? for help] ******************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
The install-config.yaml will be deleted when you will run the “openshift-install create cluster” command. The file install-config.yaml contains a generated X509 certificated valid only 24 hours. If you want to redeploy your OCP cluster, you can reuse this file only during one day or regenerate a new install-config.yaml.
Check the install-config.yaml prepared and update you “externalDNS” parameter:
(overcloud) [stack@perflab-director ~]$ cat ~/openshift/install-config.yaml
apiVersion: v1
baseDomain: lan.redhat.com
compute:
- hyperthreading: Enabled
name: worker
platform: {}
replicas: 3
controlPlane:
hyperthreading: Enabled
name: master
platform: {}
replicas: 3
metadata:
creationTimestamp: null
name: perflab
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
platform:
openstack:
cloud: openstack
computeFlavor: m1.large
externalDNS:
- "10.46.0.31"
externalNetwork: external
lbFloatingIP: 192.168.168.30
octaviaSupport: "1"
region: ""
trunkSupport: "1"
publish: External
pullSecret: '{"auths":{"cloud.openshift.com":{"auth":"xxxxx","email":"xxx@xxx.xxx"},"quay.io":{"auth":"xxxxxxxx","email":"xxx@xxx.xxx"},"registry.connect.redhat.com":{"auth":"xxxxxxxxx","email":"xxx@xxx.xxx"},"registry.redhat.io":{"auth":"xxxxxxxxxxxxxx","email":"xxx@xxx.xxx"}}}'
sshKey: ssh-rsa XXXXXXXX
e
Deployment of OpenShift, first step with the bootstrap node and three masters
Launch the OpenShift 4.3 deployment:
(overcloud) [stack@perflab-director ~]$ openshift-install create cluster --dir='/home/stack/openshift' --log-level info
INFO Obtaining RHCOS image file from 'https://releases-art-rhcos.svc.ci.openshift.org/art/storage/releases/rhcos-4.3/43.81.202001142154.0/x86_64/rhcos-43.81.202001142154.0-openstack.x86_64.qcow2.gz?sha256=504b9008adf89bb3d05b75d393e057c6d66ba6c92cf631ca4445d99bbf7e2a57'
INFO The file was found in cache: /home/stack/.cache/openshift-installer/image_cache/d03e06d2824bac47eaee911dcc5feff9. Reusing...
INFO Consuming Install Config from target directory
INFO Creating infrastructure resources...
INFO Waiting up to 30m0s for the Kubernetes API at https://api.perflab.lan.redhat.com:6443...
INFO API v1.16.2 up
INFO Waiting up to 30m0s for bootstrapping to complete...
INFO Destroying the bootstrap resources...
INFO Waiting up to 30m0s for the cluster at https://api.perflab.lan.redhat.com:6443 to initialize...
INFO Waiting up to 10m0s for the openshift-console route to be created...
INFO Install complete!
INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/home/stack/openshift/auth/kubeconfig'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.perflab.lan.redhat.com
INFO Login to the console with user: kubeadmin, password: xxxxxx-xxxxxx-xxxxxx-xxxxxx
Installation step post analysis
Let’s analyse what the OpenShift installer has done with the previous install process.
1) Image download
“INFO Obtaining RHCOS image file from ‘https://releases-art-rhcos.svc.ci.openshift.org/art/storage/releases/rhcos-4.3/43.81.202001142154.0/x86_64/rhcos-43.81.202001142154.0-openstack.x86_64.qcow2.gz?sha256=504b9008adf89bb3d05b75d393e057c6d66ba6c92cf631ca4445d99bbf7e2a57'"
(overcloud) [stack@perflab-director openshift]$ openstack image list | grep rhcos
| 49c159da-90b7-480e-ac6b-9191402606fc | perflab-f8n55-rhcos | active |
(overcloud) [stack@perflab-director openshift]$ openstack image show perflab-f8n55-rhcos
+------------------+------------------------------------------------------------------------------+
| Field | Value |
+------------------+------------------------------------------------------------------------------+
| checksum | 2e9b54493656d42271b19b8724072f0c |
| container_format | bare |
| created_at | 2020-02-14T10:27:24Z |
| disk_format | qcow2 |
| file | /v2/images/49c159da-90b7-480e-ac6b-9191402606fc/file |
| id | 49c159da-90b7-480e-ac6b-9191402606fc |
| min_disk | 0 |
| min_ram | 0 |
| name | perflab-f8n55-rhcos |
| owner | c942a792fd6f447186e5bafd6d4cbce0 |
| properties | direct_url='swift+config://ref1/glance/49c159da-90b7-480e-ac6b-9191402606fc' |
| protected | False |
| schema | /v2/schemas/image |
| size | 2131492864 |
| status | active |
| tags | openshiftClusterID=perflab-f8n55 |
| updated_at | 2020-02-14T10:27:45Z |
| virtual_size | None |
| visibility | private |
+------------------+------------------------------------------------------------------------------+
2) Configuration
During this step: “INFO Consuming Install Config from target directory” The installation read the yaml configuration file “install-config.yaml”
3) Creation of the network
During this step: “INFO Creating infrastructure resources… “, and before creating the VMs, the openshift installer is creating the internal network:
(overcloud) [stack@perflab-director openshift]$ openstack network list | grep openshift
| 3e8782cb-0cbc-4a58-a663-c186ecba6699 | perflab-f8n55-openshift | 4c9a1952-f5eb-45fb-baad-36d5d2578426 |
4) Creation of the bootstrap node
The OpenShift bootstrap is started:
(overcloud) [stack@perflab-director ~]$ openstack server list
+--------------------------------------+-------------------------+--------+---------------------------------------------------+---------------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+---------------------------------------------------+---------------------+--------------+
| 6111e7c9-f25c-468a-8612-799df187432f | perflab-f8n55-bootstrap | ACTIVE | perflab-f8n55-openshift=10.0.0.23, 192.168.168.37 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+-------------------------+--------+---------------------------------------------------+---------------------+--------------+
You can follow the bootstrap node preparation:
(overcloud) [stack@perflab-director ~]$ openstack console log show perflab-dtlt8-bootstrap
5) Creation of the master nodes
(overcloud) [stack@perflab-director ~]$ openstack server list
+--------------------------------------+-------------------------+--------+---------------------------------------------------+---------------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+---------------------------------------------------+---------------------+--------------+
| 2bf0c9b4-44e7-41d6-8108-7af266d32a94 | perflab-f8n55-master-0 | ACTIVE | perflab-f8n55-openshift=10.0.0.12 | perflab-f8n55-rhcos | m1.large |
| 6111e7c9-f25c-468a-8612-799df187432f | perflab-f8n55-bootstrap | ACTIVE | perflab-f8n55-openshift=10.0.0.23, 192.168.168.37 | perflab-f8n55-rhcos | m1.large |
| c83ec26e-da23-402c-95f0-375ee45e9cd5 | perflab-f8n55-master-2 | ACTIVE | perflab-f8n55-openshift=10.0.0.21 | perflab-f8n55-rhcos | m1.large |
| d91b4146-9dac-4976-88f1-0a497cee9310 | perflab-f8n55-master-1 | ACTIVE | perflab-f8n55-openshift=10.0.0.13 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+-------------------------+--------+---------------------------------------------------+---------------------+--------------+
We can follow the installation one OpenShift master node:
(overcloud) [stack@perflab-director ~]$ openstack console log show perflab-f8n55-master-0
...
6) Spawn of three additional OpenShift worker nodes
After this step “INFO API v1.16.2 up”, the installer is creating the workers:
+--------------------------------------+----------------------------+--------+---------------------------------------------------+---------------------+----------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+----------------------------+--------+---------------------------------------------------+---------------------+----------+
| 6111e7c9-f25c-468a-8612-799df187432f | perflab-f8n55-bootstrap | ACTIVE | perflab-f8n55-openshift=10.0.0.23, 192.168.168.37 | perflab-f8n55-rhcos | m1.large |
| 6278f420-abac-4596-9faf-521bff3ecd07 | perflab-f8n55-worker-5wk49 | ACTIVE | perflab-f8n55-openshift=10.0.0.14 | perflab-f8n55-rhcos | m1.large |
| 9c016b26-30b4-460d-a971-9b1009ad0967 | perflab-f8n55-worker-hpfcl | ACTIVE | perflab-f8n55-openshift=10.0.0.18 | perflab-f8n55-rhcos | m1.large |
| 3e54f1c9-a66d-4517-b372-5dde6bc35875 | perflab-f8n55-worker-bt9qk | ACTIVE | perflab-f8n55-openshift=10.0.0.31 | perflab-f8n55-rhcos | m1.large |
| 2bf0c9b4-44e7-41d6-8108-7af266d32a94 | perflab-f8n55-master-0 | ACTIVE | perflab-f8n55-openshift=10.0.0.12 | perflab-f8n55-rhcos | m1.large |
| c83ec26e-da23-402c-95f0-375ee45e9cd5 | perflab-f8n55-master-2 | ACTIVE | perflab-f8n55-openshift=10.0.0.21 | perflab-f8n55-rhcos | m1.large |
| d91b4146-9dac-4976-88f1-0a497cee9310 | perflab-f8n55-master-1 | ACTIVE | perflab-f8n55-openshift=10.0.0.13 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+-------------------------+--------+------------------------------------------------------+---------------------+----------+
7) Last step bootstrap node is deleted
The OpenShift bootstrap node is deleted:
(overcloud) [stack@perflab-director openshift]$ openstack server list
+--------------------------------------+----------------------------+--------+-----------------------------------+---------------------+----------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+----------------------------+--------+-----------------------------------+---------------------+----------+
| 6278f420-abac-4596-9faf-521bff3ecd07 | perflab-f8n55-worker-5wk49 | ACTIVE | perflab-f8n55-openshift=10.0.0.14 | perflab-f8n55-rhcos | m1.large |
| 9c016b26-30b4-460d-a971-9b1009ad0967 | perflab-f8n55-worker-hpfcl | ACTIVE | perflab-f8n55-openshift=10.0.0.18 | perflab-f8n55-rhcos | m1.large |
| 3e54f1c9-a66d-4517-b372-5dde6bc35875 | perflab-f8n55-worker-bt9qk | ACTIVE | perflab-f8n55-openshift=10.0.0.31 | perflab-f8n55-rhcos | m1.large |
| 2bf0c9b4-44e7-41d6-8108-7af266d32a94 | perflab-f8n55-master-0 | ACTIVE | perflab-f8n55-openshift=10.0.0.12 | perflab-f8n55-rhcos | m1.large |
| c83ec26e-da23-402c-95f0-375ee45e9cd5 | perflab-f8n55-master-2 | ACTIVE | perflab-f8n55-openshift=10.0.0.21 | perflab-f8n55-rhcos | m1.large |
| d91b4146-9dac-4976-88f1-0a497cee9310 | perflab-f8n55-master-1 | ACTIVE | perflab-f8n55-openshift=10.0.0.13 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+----------------------------+--------+-----------------------------------+---------------------+----------+
Check the OpenShift deployment
The OpenShift API is now listening on port 6443:
[stack@perflab-director ~]$ curl --insecure https://api.perflab.lan.redhat.com:6443
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/\"",
"reason": "Forbidden",
"details": {
},
"code": 403
}
Look the kubeconfig generated:
(overcloud) [stack@perflab-director ~]$ cat /home/stack/openshift/auth/kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
server: https://api.perflab.lan.redhat.com:6443
name: perflab
contexts:
- context:
cluster: perflab
user: admin
name: admin
current-context: admin
kind: Config
preferences: {}
users:
- name: admin
user:
client-certificate-data: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
client-key-data: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Load OpenShift environment variables:
[stack@perflab-director ~]$ export KUBECONFIG=/home/stack/openshift/auth/kubeconfig
Check the OpenShift version:
[stack@perflab-director ~]$ oc get clusterversion
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.3.1 True False 5m57s Cluster version is 4.3.1
[stack@perflab-director ~]$ oc get pods -n openshift-openstack-infra
NAME READY STATUS RESTARTS AGE
coredns-perflab-f8n55-master-0 1/1 Running 0 23m
coredns-perflab-f8n55-master-1 1/1 Running 0 23m
coredns-perflab-f8n55-master-2 1/1 Running 0 22m
coredns-perflab-f8n55-worker-5wk49 1/1 Running 0 7m12s
coredns-perflab-f8n55-worker-bt9qk 1/1 Running 0 13m
coredns-perflab-f8n55-worker-hpfcl 1/1 Running 0 11m
haproxy-perflab-f8n55-master-0 2/2 Running 0 24m
haproxy-perflab-f8n55-master-1 2/2 Running 0 23m
haproxy-perflab-f8n55-master-2 2/2 Running 0 22m
keepalived-perflab-f8n55-master-0 1/1 Running 0 23m
keepalived-perflab-f8n55-master-1 1/1 Running 0 24m
keepalived-perflab-f8n55-master-2 1/1 Running 0 24m
keepalived-perflab-f8n55-worker-5wk49 1/1 Running 0 6m57s
keepalived-perflab-f8n55-worker-bt9qk 1/1 Running 0 13m
keepalived-perflab-f8n55-worker-hpfcl 1/1 Running 0 11m
mdns-publisher-perflab-f8n55-master-0 1/1 Running 0 24m
mdns-publisher-perflab-f8n55-master-1 1/1 Running 0 23m
mdns-publisher-perflab-f8n55-master-2 1/1 Running 0 22m
mdns-publisher-perflab-f8n55-worker-5wk49 1/1 Running 0 7m9s
mdns-publisher-perflab-f8n55-worker-bt9qk 1/1 Running 0 13m
mdns-publisher-perflab-f8n55-worker-hpfcl 1/1 Running 0 11m
Now with the same floating IP we can connect on the master vIP:
[stack@perflab-director ~]$ ssh core@192.168.168.30
The authenticity of host '192.168.168.30 (192.168.168.30)' can't be established.
ECDSA key fingerprint is SHA256:MuVgW5eYDTV7dgzKRyL6RWacykvEtxwhw+HQJwZhTC0.
ECDSA key fingerprint is MD5:f9:8a:aa:0b:82:37:4f:73:27:8a:14:97:8b:dc:7c:a0.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.168.30' (ECDSA) to the list of known hosts.
Red Hat Enterprise Linux CoreOS 43.81.202002032142.0
Part of OpenShift 4.3, RHCOS is a Kubernetes native operating system
managed by the Machine Config Operator (`clusteroperator/machine-config`).
WARNING: Direct SSH access to machines is not recommended; instead,
make configuration changes via `machineconfig` objects:
https://docs.openshift.com/container-platform/4.3/architecture/architecture-rhcos.html
---
[core@perflab-f8n55-master-1 ~]$ uptime
11:01:24 up 29 min, 1 user, load average: 1.61, 1.35, 1.19
[core@perflab-f8n55-master-1 ~]$ cat /etc/redhat-release
Red Hat Enterprise Linux CoreOS release 4.3
[core@perflab-f8n55-master-1 ~]$ uname -a
Linux perflab-f8n55-master-1 4.18.0-147.3.1.el8_1.x86_64 #1 SMP Wed Nov 27 01:11:44 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
List OpenShift nodes:
[stack@perflab-director ~]$ oc get nodes
NAME STATUS ROLES AGE VERSION
perflab-f8n55-master-0 Ready master 25m v1.16.2
perflab-f8n55-master-1 Ready master 25m v1.16.2
perflab-f8n55-master-2 Ready master 25m v1.16.2
perflab-f8n55-worker-5wk49 Ready worker 9m3s v1.16.2
perflab-f8n55-worker-bt9qk Ready worker 15m v1.16.2
perflab-f8n55-worker-hpfcl Ready worker 13m v1.16.2
List the OpenStack security groups:
(overcloud) [stack@perflab-director ~]$ openstack security group list
+--------------------------------------+-----------------------+------------------------+----------------------------------+
| ID | Name | Description | Project |
+--------------------------------------+-----------------------+------------------------+----------------------------------+
| 29789b3e-6b9e-41cf-82ba-55ebba5dfd76 | lb-health-mgr-sec-grp | lb-health-mgr-sec-grp | be3b187d3a264957bc2320cf77c55681 |
| 2bd58d26-1e79-4e43-a229-bc5b930c447a | perflab-f8n55-worker | | c942a792fd6f447186e5bafd6d4cbce0 |
| 2cb57630-29ce-4376-9850-0da170f738f2 | default | Default security group | be3b187d3a264957bc2320cf77c55681 |
| 2f453b24-7b3f-43c0-8c43-d9520cd74680 | default | Default security group | c942a792fd6f447186e5bafd6d4cbce0 |
| 50bc9acc-7942-41a3-962f-aa511085f3f8 | default | Default security group | |
| 8d043d37-4f20-4690-ad94-485eaf887dea | perflab-f8n55-master | | c942a792fd6f447186e5bafd6d4cbce0 |
| 93cb85c9-5821-47e8-ad85-de18706d63f5 | web | Web servers | c942a792fd6f447186e5bafd6d4cbce0 |
| cdae4bda-7040-4fc3-b28f-e7555e2225e4 | lb-mgmt-sec-grp | lb-mgmt-sec-grp | be3b187d3a264957bc2320cf77c55681 |
+--------------------------------------+-----------------------+------------------------+----------------------------------+
List OpenStack trunks:
(overcloud) [stack@perflab-director ~]$ openstack network trunk list
+--------------------------------------+------------------------------+--------------------------------------+-------------+
| ID | Name | Parent Port | Description |
+--------------------------------------+------------------------------+--------------------------------------+-------------+
| 139066c1-af72-441c-8316-20ea8376bc7e | perflab-f8n55-master-trunk-1 | e8e84615-f013-43aa-9486-cf0f2ca1b421 | |
| 7dd781f1-4d08-4ef2-a0e5-fc9295d26413 | perflab-f8n55-master-trunk-2 | 25fc0777-2405-4bf4-94fd-eccae4c7d3fd | |
| 9726a823-d970-4745-9625-0ea5e47ff182 | perflab-f8n55-worker-5wk49 | b74dcf4f-e301-43da-a0ac-ad9ba6de641e | |
| 9898a8cb-4520-47b5-8531-2cbfd5aadc9e | perflab-f8n55-worker-hpfcl | 32860ac8-ce3f-4e3d-b5c9-080a152841be | |
| b00bcfbf-87fe-452d-b851-248d54555f9b | perflab-f8n55-master-trunk-0 | 23437211-b5df-42e1-8b7b-a5924ee4334e | |
| ee1712ad-549e-4825-977c-3771b7a8d6ce | perflab-f8n55-worker-bt9qk | e2005924-6194-42e0-a49b-8dbff87a0793 | |
+--------------------------------------+------------------------------+--------------------------------------+-------------+
Detail of the OpenStack trunk:
(overcloud) [stack@perflab-director ~]$ openstack network trunk show perflab-f8n55-master-trunk-0
+-----------------+---------------------------------------+
| Field | Value |
+-----------------+---------------------------------------+
| admin_state_up | UP |
| created_at | 2020-02-14T10:27:47Z |
| description | |
| id | b00bcfbf-87fe-452d-b851-248d54555f9b |
| name | perflab-f8n55-master-trunk-0 |
| port_id | 23437211-b5df-42e1-8b7b-a5924ee4334e |
| project_id | c942a792fd6f447186e5bafd6d4cbce0 |
| revision_number | 2 |
| status | ACTIVE |
| sub_ports | |
| tags | [u'openshiftClusterID=perflab-f8n55'] |
| tenant_id | c942a792fd6f447186e5bafd6d4cbce0 |
| updated_at | 2020-02-14T10:28:27Z |
+-----------------+---------------------------------------+
(overcloud) [stack@perflab-director ~]$ openstack port show 23437211-b5df-42e1-8b7b-a5924ee4334e
+-----------------------+--------------------------------------------------------------------------------------------------+
| Field | Value |
+-----------------------+--------------------------------------------------------------------------------------------------+
| admin_state_up | UP |
| allowed_address_pairs | ip_address='10.0.0.5', mac_address='fa:16:3e:d1:5d:d6' |
| | ip_address='10.0.0.6', mac_address='fa:16:3e:d1:5d:d6' |
| | ip_address='10.0.0.7', mac_address='fa:16:3e:d1:5d:d6' |
| binding_host_id | overcloud-compute-0.lan.redhat.com |
| binding_profile | |
| binding_vif_details | bridge_name='tbr-b00bcfbf-8', datapath_type='system', ovs_hybrid_plug='True', port_filter='True' |
| binding_vif_type | ovs |
| binding_vnic_type | normal |
| created_at | 2020-02-14T10:27:37Z |
| data_plane_status | None |
| description | |
| device_id | 2bf0c9b4-44e7-41d6-8108-7af266d32a94 |
| device_owner | compute:nova |
| dns_assignment | None |
| dns_name | None |
| extra_dhcp_opts | ip_version='4', opt_name='domain-search', opt_value='perflab.lan.redhat.com' |
| fixed_ips | ip_address='10.0.0.12', subnet_id='4c9a1952-f5eb-45fb-baad-36d5d2578426' |
| id | 23437211-b5df-42e1-8b7b-a5924ee4334e |
| ip_address | None |
| mac_address | fa:16:3e:d1:5d:d6 |
| name | perflab-f8n55-master-port-0 |
| network_id | 3e8782cb-0cbc-4a58-a663-c186ecba6699 |
| option_name | None |
| option_value | None |
| port_security_enabled | True |
| project_id | c942a792fd6f447186e5bafd6d4cbce0 |
| qos_policy_id | None |
| revision_number | 14 |
| security_group_ids | 8d043d37-4f20-4690-ad94-485eaf887dea |
| status | ACTIVE |
| subnet_id | None |
| tags | openshiftClusterID=perflab-f8n55 |
| trunk_details | {u'trunk_id': u'b00bcfbf-87fe-452d-b851-248d54555f9b', u'sub_ports': []} |
| updated_at | 2020-02-14T10:28:29Z |
+-----------------------+--------------------------------------------------------------------------------------------------+
The DNS entry “console-openshift-console.apps.perflab.lan.redhat.com” is pointing to 10.0.0.7:
(overcloud) [stack@perflab-director ~]$ ssh -o "StrictHostKeyChecking=no" core@192.168.168.30
Red Hat Enterprise Linux CoreOS 43.81.202002032142.0
Part of OpenShift 4.3, RHCOS is a Kubernetes native operating system
managed by the Machine Config Operator (`clusteroperator/machine-config`).
WARNING: Direct SSH access to machines is not recommended; instead,
make configuration changes via `machineconfig` objects:
https://docs.openshift.com/container-platform/4.3/architecture/architecture-rhcos.html
---
Last login: Fri Feb 14 11:01:13 2020 from 192.168.168.2
[core@perflab-f8n55-master-1 ~]$ dig console-openshift-console.apps.perflab.lan.redhat.com
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el8 <<>> console-openshift-console.apps.perflab.lan.redhat.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32224
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 9d310df98d2cba51 (echoed)
;; QUESTION SECTION:
;console-openshift-console.apps.perflab.lan.redhat.com. IN A
;; ANSWER SECTION:
console-openshift-console.apps.perflab.lan.redhat.com. 30 IN A 10.0.0.7
;; Query time: 0 msec
;; SERVER: 10.0.0.6#53(10.0.0.6)
;; WHEN: Fri Feb 14 11:03:53 UTC 2020
;; MSG SIZE rcvd: 163
List OpenStack floating IPs:
(overcloud) [stack@perflab-director ~]$ openstack floating ip list
+--------------------------------------+---------------------+------------------+--------------------------------------+--------------------------------------+----------------------------------+
| ID | Floating IP Address | Fixed IP Address | Port | Floating Network | Project |
+--------------------------------------+---------------------+------------------+--------------------------------------+--------------------------------------+----------------------------------+
| 215a6925-84f2-40fa-897a-44ce53f01dea | 192.168.168.41 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 274fa26b-1aa4-48c2-a6c5-0c07ecd62429 | 192.168.168.23 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 28965300-a668-4348-b2a0-f51660735383 | 192.168.168.44 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 290c7e9d-0c88-47ea-b214-36b93a77672d | 192.168.168.21 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 2c36f3d3-53fc-4c79-a0ee-32d92b4ff27b | 192.168.168.30 | 10.0.0.5 | a8eb56d7-ad47-4678-83ae-aea287cadc74 | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 3b1109ee-2a4a-46cd-acaa-213c4ee6a85c | 192.168.168.33 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 4cc948ad-d636-4370-8dab-3205fe1de992 | 192.168.168.48 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 5ae03e7d-597f-4689-83f6-0ccb7fc9758b | 192.168.168.27 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 634d7790-cae2-4261-b76d-19799826761e | 192.168.168.36 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 665fcc37-82e6-4405-b68b-09757d221c79 | 192.168.168.47 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 6853d0b9-336d-45db-ae24-3ab48a5c8c65 | 192.168.168.29 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| 6cfe8bf8-df5c-46df-9ab5-cfb4229d7823 | 192.168.168.25 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| ada5ba51-e8c3-449b-aba6-27a39c15720f | 192.168.168.26 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| c6d62f66-d4e8-4c55-8fcf-4e48e6fa4108 | 192.168.168.31 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| e03bdb6c-c508-444e-8e3d-730a26f1dfb0 | 192.168.168.22 | None | None | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
+--------------------------------------+---------------------+------------------+--------------------------------------+--------------------------------------+----------------------------------+
Get ingress-port port ID:
(overcloud) [stack@perflab-director ~]$ openstack port list | grep "ingress-port"
| 18ea91ca-593a-479b-b202-79fa46df48b8 | perflab-f8n55-ingress-port | fa:16:3e:b0:08:2c | ip_address='10.0.0.7', subnet_id='4c9a1952-f5eb-45fb-baad-36d5d2578426' | DOWN |
Enable one OpenStack Floating IP to the console and application:
(overcloud) [stack@perflab-director ~]$ openstack floating ip set --port 18ea91ca-593a-479b-b202-79fa46df48b8 192.168.168.31
(overcloud) [stack@perflab-director ~]$ openstack floating ip list | grep 10.0.0
| 2c36f3d3-53fc-4c79-a0ee-32d92b4ff27b | 192.168.168.30 | 10.0.0.5 | d049025b-8795-4a99-b276-f990ac2b9cc0 | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
| c6d62f66-d4e8-4c55-8fcf-4e48e6fa4108 | 192.168.168.31 | 10.0.0.7 | 18ea91ca-593a-479b-b202-79fa46df48b8 | 211ae1cd-eb6b-4360-ae7b-027fd66f86d1 | c942a792fd6f447186e5bafd6d4cbce0 |
Scan the ports \o/ Success:
(overcloud) [stack@perflab-director ~]$ sudo nmap console-openshift-console.apps.perflab.lan.redhat.com
Starting Nmap 6.40 ( http://nmap.org ) at 2020-02-14 06:11 EST
Nmap scan report for console-openshift-console.apps.perflab.lan.redhat.com (192.168.168.31)
Host is up (0.00089s latency).
Not shown: 997 filtered ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
443/tcp open https
Nmap done: 1 IP address (1 host up) scanned in 4.63 seconds
On your laptop, add the domain names entries in your /etc/hosts:
egallen@laptop ~ % sudo tee -a /etc/hosts << EOF
192.168.168.30 api.perflab.lan.redhat.com
192.168.168.31 console-openshift-console.apps.perflab.lan.redhat.com
192.168.168.31 oauth-openshift.apps.perflab.lan.redhat.com
192.168.168.31 grafana-default.apps.perflab.lan.redhat.com
192.168.168.31 prometheus-default.apps.perflab.lan.redhat.com
EOF
Launch a tunnel:
egallen@laptop ~ % brew install sshuttle
egallen@laptop ~ % sshuttle -r perflab-director 192.168.168.0/24
Connect to the console
We can connect to the console in a browser, console URL : https://console-openshift-console.apps.perflab.lan.redhat.com
OpenShift 4.3 console prompt:

OpenShift 4.3 console home:

OpenShift 4.3 console developer:

Adding a GPU worker node
Now we have a set of master and worker nodes, but we want to add a GPU worker node using an OpenStack instance with GPU passthrough.
Check the current list of OpenShift machines:
[stack@perflab-director ~]$ oc get machines -n openshift-machine-api
NAME PHASE TYPE REGION ZONE AGE
perflab-f8n55-master-0 Running m1.large regionOne nova 36m
perflab-f8n55-master-1 Running m1.large regionOne nova 36m
perflab-f8n55-master-2 Running m1.large regionOne nova 36m
perflab-f8n55-worker-5wk49 Running m1.large regionOne nova 31m
perflab-f8n55-worker-bt9qk Running m1.large regionOne nova 31m
perflab-f8n55-worker-hpfcl Running m1.large regionOne nova 31m
Check the current list of OpenShift machinesets:
[stack@perflab-director ~]$ oc get machinesets -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
perflab-f8n55-worker 3 3 3 3 36m
Copy an the existing worker machine set definition for a GPU-enabled worker machine set definition.
[stack@perflab-director openshift]$ oc get machineset perflab-f8n55-worker -n openshift-machine-api -o json > perflab-f8n55-worker.json
[stack@perflab-director openshift]$ cp perflab-f8n55-worker.json perflab-f8n55-worker-gpu.json
Change the flavor in the GPU machineset type with NVIDIA V100 GPU, reduce the replicas from 3 to 1, replace the flavor from m1.large to m1-gpu.large, remove creationTimestamp and uid entries:
(overcloud) [stack@perflab-director openshift]$ sed -i 's/m1.large/m1-gpu.large/' perflab-f8n55-worker-gpu.json
(overcloud) [stack@perflab-director openshift]$ sed -i 's/machine.openshift.io\/cluster-api-machineset\":\ \"perflab-f8n55-worker/machine.openshift.io\/cluster-api-machineset\":\ \"perflab-f8n55-worker-gpu/' perflab-f8n55-worker-gpu.json
(overcloud) [stack@perflab-director openshift]$ sed -i 's/\"replicas\":\ 3/\"replicas\":\ 1/' perflab-f8n55-worker-gpu.json
(overcloud) [stack@perflab-director openshift]$ sed -i 's/\"availableReplicas\":\ 3/\"availableReplicas\":\ 1/' perflab-f8n55-worker-gpu.json
(overcloud) [stack@perflab-director openshift]$ sed -i 's/\"fullyLabeledReplicas\":\ 3/\"fullyLabeledReplicas\":\ 1/' perflab-f8n55-worker-gpu.json
(overcloud) [stack@perflab-director openshift]$ sed -i 's/\"readyReplicas\":\ 3/\"readyReplicas\":\ 1/' perflab-f8n55-worker-gpu.json
...
Other changes
- rename perflab-f8n55-worker to perflab-f8n55-worker-gpu “name”: “perflab-f8n55-worker-gpu”,
- rename selflink and comma “selfLink”: “/apis/machine.openshift.io/v1beta1/namespaces/openshift-machine-api/machinesets/perflab-f8n55-worker-gpu”
- remove uid entry
- remove creationTimestamp entry
Check the diff:
[stack@perflab-director openshift]$ diff perflab-f8n55-worker.json perflab-f8n55-worker-gpu.json
5d4
< "creationTimestamp": "2020-02-14T10:36:31Z",
12c11
< "name": "perflab-f8n55-worker",
---
> "name": "perflab-f8n55-worker-gpu",
15,16c14
< "selfLink": "/apis/machine.openshift.io/v1beta1/namespaces/openshift-machine-api/machinesets/perflab-f8n55-worker",
< "uid": "4eb05de5-7c9f-47a1-b7cd-9f34a630ad6a"
---
> "selfLink": "/apis/machine.openshift.io/v1beta1/namespaces/openshift-machine-api/machinesets/perflab-f8n55-worker-gpu",
19c17
< "replicas": 3,
---
> "replicas": 1,
23c21
< "machine.openshift.io/cluster-api-machineset": "perflab-f8n55-worker"
---
> "machine.openshift.io/cluster-api-machineset": "perflab-f8n55-worker-gpu"
33c31
< "machine.openshift.io/cluster-api-machineset": "perflab-f8n55-worker"
---
> "machine.openshift.io/cluster-api-machineset": "perflab-f8n55-worker-gpu"
48c46
< "flavor": "m1.large",
---
> "flavor": "m1-gpu.large",
90,91c88,89
< "availableReplicas": 3,
< "fullyLabeledReplicas": 3,
---
> "availableReplicas": 1,
> "fullyLabeledReplicas": 1,
93,94c91,92
< "readyReplicas": 3,
< "replicas": 3
---
> "readyReplicas": 1,
> "replicas": 1
Create a new GPU flavor:
(overcloud) [stack@perflab-director ~]$ openstack flavor create --ram 32768 --disk 200 --vcpus 4 m1-gpu.large
+----------------------------+--------------------------------------+
| Field | Value |
+----------------------------+--------------------------------------+
| OS-FLV-DISABLED:disabled | False |
| OS-FLV-EXT-DATA:ephemeral | 0 |
| disk | 200 |
| id | 5c6843b5-89ae-4fe8-92c5-fac5a707c241 |
| name | m1-gpu.large |
| os-flavor-access:is_public | True |
| properties | |
| ram | 32768 |
| rxtx_factor | 1.0 |
| swap | |
| vcpus | 4 |
+----------------------------+--------------------------------------+
Set the alias to the OpenStack flavor:
(overcloud) [stack@perflab-director ~]$ openstack flavor set m1-gpu.large --property "pci_passthrough:alias"="v100:1"
Try to boot a RHEL77 instance with this flavor:
(overcloud) [stack@perflab-director templates]$ openstack server create --flavor m1-gpu.large --image rhel77 --security-group web --nic net-id=perflab-x7szb-openshift --key-name lambda instance0
+-------------------------------------+-----------------------------------------------------+
| Field | Value |
+-------------------------------------+-----------------------------------------------------+
| OS-DCF:diskConfig | MANUAL |
| OS-EXT-AZ:availability_zone | |
| OS-EXT-SRV-ATTR:host | None |
| OS-EXT-SRV-ATTR:hypervisor_hostname | None |
| OS-EXT-SRV-ATTR:instance_name | |
| OS-EXT-STS:power_state | NOSTATE |
| OS-EXT-STS:task_state | scheduling |
| OS-EXT-STS:vm_state | building |
| OS-SRV-USG:launched_at | None |
| OS-SRV-USG:terminated_at | None |
| accessIPv4 | |
| accessIPv6 | |
| addresses | |
| adminPass | J886yg7sz7MP |
| config_drive | |
| created | 2019-10-27T11:10:26Z |
| flavor | m1-gpu.large (5c6843b5-89ae-4fe8-92c5-fac5a707c241) |
| hostId | |
| id | ad86a6cf-6115-4944-88c1-568c1bc58da0 |
| image | rhel77 (ad740f80-83ad-4af3-8fe7-f255276c0453) |
| key_name | lambda |
| name | instance0 |
| progress | 0 |
| project_id | c942a792fd6f447186e5bafd6d4cbce0 |
| properties | |
| security_groups | name='93cb85c9-5821-47e8-ad85-de18706d63f5' |
| status | BUILD |
| updated | 2019-10-27T11:10:26Z |
| user_id | 721b251122304444bfee09c97f441042 |
| volumes_attached | |
+-------------------------------------+-----------------------------------------------------+
(overcloud) [stack@perflab-director ~]$ FLOATING_IP_ID=$( openstack floating ip list -f value -c ID --status 'DOWN' | head -n 1 )
(overcloud) [stack@perflab-director ~]$ openstack server add floating ip instance0 $FLOATING_IP_ID
(overcloud) [stack@perflab-director ~]$ openstack server list
+--------------------------------------+----------------------------+--------+---------------------------------------------------+--------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+----------------------------+--------+---------------------------------------------------+--------+--------------+
| c4cab741-6c4c-4360-8b52-23429d9832d9 | perflab-x7szb-worker-2jqns | ACTIVE | perflab-x7szb-openshift=10.0.0.16 | rhcos | m1.large |
| 777cdf85-93f7-41fa-886f-60171e4e0151 | perflab-x7szb-worker-7gk2p | ACTIVE | perflab-x7szb-openshift=10.0.0.37 | rhcos | m1.large |
| 4edf8110-26ff-42b3-880e-56dcbf43762c | perflab-x7szb-worker-v6xwp | ACTIVE | perflab-x7szb-openshift=10.0.0.20 | rhcos | m1.large |
| e4fa8300-b24c-4d64-95fb-2b0c19c86b17 | perflab-x7szb-master-0 | ACTIVE | perflab-x7szb-openshift=10.0.0.13 | rhcos | m1.large |
| f56b855a-f02c-4b42-9009-b3b3078c3890 | perflab-x7szb-master-2 | ACTIVE | perflab-x7szb-openshift=10.0.0.29 | rhcos | m1.large |
| dcc0b4d3-97ec-4c6a-b841-558c1bb535a3 | perflab-x7szb-master-1 | ACTIVE | perflab-x7szb-openshift=10.0.0.22 | rhcos | m1.large |
+--------------------------------------+----------------------------+--------+---------------------------------------------------+--------+--------------+
(overcloud) [stack@perflab-director openshift]$ openstack server list
+--------------------------------------+----------------------------+--------+---------------------------------------------------+---------------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+----------------------------+--------+---------------------------------------------------+---------------------+--------------+
| ad86a6cf-6115-4944-88c1-568c1bc58da0 | instance0 | ACTIVE | perflab-x7szb-openshift=10.0.0.12, 192.168.168.41 | rhel77 | m1-gpu.large |
| 22f0cde9-4de2-4db0-802a-7f78c8f402e7 | perflab-dtlt8-worker-tctxg | ACTIVE | perflab-dtlt8-openshift=10.0.0.20 | perflab-dtlt8-rhcos | m1.large |
| 4f4e5cea-be2f-45b1-8b15-6877c2041285 | perflab-dtlt8-worker-2shth | ACTIVE | perflab-dtlt8-openshift=10.0.0.16 | perflab-dtlt8-rhcos | m1.large |
| 60f9c360-b961-4559-8d47-ddda0d7303a6 | perflab-dtlt8-worker-g4jd5 | ACTIVE | perflab-dtlt8-openshift=10.0.0.14 | perflab-dtlt8-rhcos | m1.large |
| 375ac995-2751-4131-bdb2-e3fc8eb96f77 | perflab-dtlt8-master-2 | ACTIVE | perflab-dtlt8-openshift=10.0.0.13 | perflab-dtlt8-rhcos | m1.large |
| 8d8e70a5-0376-4514-b0c6-61e950bfcd80 | perflab-dtlt8-master-1 | ACTIVE | perflab-dtlt8-openshift=10.0.0.28 | perflab-dtlt8-rhcos | m1.large |
| e63bb722-cf3d-480f-9713-670c012fcd0b | perflab-dtlt8-master-0 | ACTIVE | perflab-dtlt8-openshift=10.0.0.11 | perflab-dtlt8-rhcos | m1.large |
+--------------------------------------+----------------------------+--------+---------------------------------------------------+---------------------+--------------+
Connect to the instance to check if we can find the GPU device:
(overcloud) [stack@perflab-director ~]$ ssh cloud-user@192.168.168.41
[cloud-user@instance0 ~]$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.7 (Maipo)
[cloud-user@instance0 ~]$ sudo lspci | grep -i nvidia
00:05.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] (rev a1)
We are good the OSP passthrough is working, we can delete this instance:
(overcloud) [stack@perflab-director ~]$ openstack server delete instance0
List the existing OpenStack nodes before adding the new machineset:
(overcloud) [stack@perflab-director openshift]$ openstack server list
+--------------------------------------+----------------------------+--------+-----------------------------------+---------------------+----------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+----------------------------+--------+-----------------------------------+---------------------+----------+
| 22f0cde9-4de2-4db0-802a-7f78c8f402e7 | perflab-dtlt8-worker-tctxg | ACTIVE | perflab-dtlt8-openshift=10.0.0.20 | perflab-dtlt8-rhcos | m1.large |
| 4f4e5cea-be2f-45b1-8b15-6877c2041285 | perflab-dtlt8-worker-2shth | ACTIVE | perflab-dtlt8-openshift=10.0.0.16 | perflab-dtlt8-rhcos | m1.large |
| 60f9c360-b961-4559-8d47-ddda0d7303a6 | perflab-dtlt8-worker-g4jd5 | ACTIVE | perflab-dtlt8-openshift=10.0.0.14 | perflab-dtlt8-rhcos | m1.large |
| 375ac995-2751-4131-bdb2-e3fc8eb96f77 | perflab-dtlt8-master-2 | ACTIVE | perflab-dtlt8-openshift=10.0.0.13 | perflab-dtlt8-rhcos | m1.large |
| 8d8e70a5-0376-4514-b0c6-61e950bfcd80 | perflab-dtlt8-master-1 | ACTIVE | perflab-dtlt8-openshift=10.0.0.28 | perflab-dtlt8-rhcos | m1.large |
| e63bb722-cf3d-480f-9713-670c012fcd0b | perflab-dtlt8-master-0 | ACTIVE | perflab-dtlt8-openshift=10.0.0.11 | perflab-dtlt8-rhcos | m1.large |
+--------------------------------------+----------------------------+--------+-----------------------------------+---------------------+----------+
Import the OpenShift GPU worker machine set:
[stack@perflab-director openshift]$ oc create -f perflab-f8n55-worker-gpu.json
machineset.machine.openshift.io/perflab-f8n55-worker-gpu created
Check the build:
(overcloud) [stack@perflab-director ~]$ openstack server list
+--------------------------------------+--------------------------------+--------+-----------------------------------+---------------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+--------------------------------+--------+-----------------------------------+---------------------+--------------+
| e5a2f56a-f820-4903-898b-f99b61514ae8 | perflab-f8n55-worker-gpu-jbx27 | ACTIVE | perflab-f8n55-openshift=10.0.0.28 | perflab-f8n55-rhcos | m1-gpu.large |
| 6278f420-abac-4596-9faf-521bff3ecd07 | perflab-f8n55-worker-5wk49 | ACTIVE | perflab-f8n55-openshift=10.0.0.14 | perflab-f8n55-rhcos | m1.large |
| 9c016b26-30b4-460d-a971-9b1009ad0967 | perflab-f8n55-worker-hpfcl | ACTIVE | perflab-f8n55-openshift=10.0.0.18 | perflab-f8n55-rhcos | m1.large |
| 3e54f1c9-a66d-4517-b372-5dde6bc35875 | perflab-f8n55-worker-bt9qk | ACTIVE | perflab-f8n55-openshift=10.0.0.31 | perflab-f8n55-rhcos | m1.large |
| 2bf0c9b4-44e7-41d6-8108-7af266d32a94 | perflab-f8n55-master-0 | ACTIVE | perflab-f8n55-openshift=10.0.0.12 | perflab-f8n55-rhcos | m1.large |
| c83ec26e-da23-402c-95f0-375ee45e9cd5 | perflab-f8n55-master-2 | ACTIVE | perflab-f8n55-openshift=10.0.0.21 | perflab-f8n55-rhcos | m1.large |
| d91b4146-9dac-4976-88f1-0a497cee9310 | perflab-f8n55-master-1 | ACTIVE | perflab-f8n55-openshift=10.0.0.13 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+--------------------------------+--------+-----------------------------------+---------------------+--------------+
List OpenShift machinesets:
(overcloud) [stack@perflab-director ~]$ oc get machinesets -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
perflab-f8n55-worker 3 3 3 3 54m
perflab-f8n55-worker-gpu 1 1 5m37s
(overcloud) [stack@perflab-director ~]$ oc get nodes
NAME STATUS ROLES AGE VERSION
perflab-f8n55-master-0 Ready master 54m v1.16.2
perflab-f8n55-master-1 Ready master 54m v1.16.2
perflab-f8n55-master-2 Ready master 53m v1.16.2
perflab-f8n55-worker-5wk49 Ready worker 37m v1.16.2
perflab-f8n55-worker-bt9qk Ready worker 44m v1.16.2
perflab-f8n55-worker-gpu-jbx27 NotReady worker 21s v1.16.2
perflab-f8n55-worker-hpfcl Ready worker 42m v1.16.2
(overcloud) [stack@perflab-director ~]$ oc get machines -n openshift-machine-api
NAME PHASE TYPE REGION ZONE AGE
perflab-f8n55-master-0 Running m1.large regionOne nova 54m
perflab-f8n55-master-1 Running m1.large regionOne nova 54m
perflab-f8n55-master-2 Running m1.large regionOne nova 54m
perflab-f8n55-worker-5wk49 Running m1.large regionOne nova 49m
perflab-f8n55-worker-bt9qk Running m1.large regionOne nova 49m
perflab-f8n55-worker-gpu-jbx27 Running m1-gpu.large regionOne nova 6m3s
perflab-f8n55-worker-hpfcl Running m1.large regionOne nova 49m
Check the status during the deployment:
(overcloud) [stack@perflab-director ~]$ oc -n openshift-machine-api get machinesets | grep gpu
perflab-f8n55-worker-gpu 1 1 1 1 6m16s
(overcloud) [stack@perflab-director ~]$ openstack console log show perflab-f8n55-worker-gpu-jbx27
...
One additional worker is spawned:
(overcloud) [stack@perflab-director ~]$ openstack server list
+--------------------------------------+--------------------------------+--------+-----------------------------------+---------------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+--------------------------------+--------+-----------------------------------+---------------------+--------------+
| e5a2f56a-f820-4903-898b-f99b61514ae8 | perflab-f8n55-worker-gpu-jbx27 | ACTIVE | perflab-f8n55-openshift=10.0.0.28 | perflab-f8n55-rhcos | m1-gpu.large |
| 6278f420-abac-4596-9faf-521bff3ecd07 | perflab-f8n55-worker-5wk49 | ACTIVE | perflab-f8n55-openshift=10.0.0.14 | perflab-f8n55-rhcos | m1.large |
| 9c016b26-30b4-460d-a971-9b1009ad0967 | perflab-f8n55-worker-hpfcl | ACTIVE | perflab-f8n55-openshift=10.0.0.18 | perflab-f8n55-rhcos | m1.large |
| 3e54f1c9-a66d-4517-b372-5dde6bc35875 | perflab-f8n55-worker-bt9qk | ACTIVE | perflab-f8n55-openshift=10.0.0.31 | perflab-f8n55-rhcos | m1.large |
| 2bf0c9b4-44e7-41d6-8108-7af266d32a94 | perflab-f8n55-master-0 | ACTIVE | perflab-f8n55-openshift=10.0.0.12 | perflab-f8n55-rhcos | m1.large |
| c83ec26e-da23-402c-95f0-375ee45e9cd5 | perflab-f8n55-master-2 | ACTIVE | perflab-f8n55-openshift=10.0.0.21 | perflab-f8n55-rhcos | m1.large |
| d91b4146-9dac-4976-88f1-0a497cee9310 | perflab-f8n55-master-1 | ACTIVE | perflab-f8n55-openshift=10.0.0.13 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+--------------------------------+--------+-----------------------------------+---------------------+--------------+
(overcloud) [stack@perflab-director ~]$ FLOATING_IP_ID=$( openstack floating ip list -f value -c ID --status 'DOWN' | head -n 1 )
(overcloud) [stack@perflab-director ~]$ openstack server add floating ip perflab-f8n55-worker-gpu-jbx27 $FLOATING_IP_ID
(overcloud) [stack@perflab-director ~]$ openstack server list
+--------------------------------------+--------------------------------+--------+---------------------------------------------------+---------------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+--------------------------------+--------+---------------------------------------------------+---------------------+--------------+
| e5a2f56a-f820-4903-898b-f99b61514ae8 | perflab-f8n55-worker-gpu-jbx27 | ACTIVE | perflab-f8n55-openshift=10.0.0.28, 192.168.168.41 | perflab-f8n55-rhcos | m1-gpu.large |
| 6278f420-abac-4596-9faf-521bff3ecd07 | perflab-f8n55-worker-5wk49 | ACTIVE | perflab-f8n55-openshift=10.0.0.14 | perflab-f8n55-rhcos | m1.large |
| 9c016b26-30b4-460d-a971-9b1009ad0967 | perflab-f8n55-worker-hpfcl | ACTIVE | perflab-f8n55-openshift=10.0.0.18 | perflab-f8n55-rhcos | m1.large |
| 3e54f1c9-a66d-4517-b372-5dde6bc35875 | perflab-f8n55-worker-bt9qk | ACTIVE | perflab-f8n55-openshift=10.0.0.31 | perflab-f8n55-rhcos | m1.large |
| 2bf0c9b4-44e7-41d6-8108-7af266d32a94 | perflab-f8n55-master-0 | ACTIVE | perflab-f8n55-openshift=10.0.0.12 | perflab-f8n55-rhcos | m1.large |
| c83ec26e-da23-402c-95f0-375ee45e9cd5 | perflab-f8n55-master-2 | ACTIVE | perflab-f8n55-openshift=10.0.0.21 | perflab-f8n55-rhcos | m1.large |
| d91b4146-9dac-4976-88f1-0a497cee9310 | perflab-f8n55-master-1 | ACTIVE | perflab-f8n55-openshift=10.0.0.13 | perflab-f8n55-rhcos | m1.large |
+--------------------------------------+--------------------------------+--------+---------------------------------------------------+---------------------+--------------+
We can connect into the worker to check the status and find the NVIDIA Tesla V100:
(overcloud) [stack@perflab-director ~]$ ssh core@192.168.168.41
The authenticity of host '192.168.168.41 (192.168.168.41)' can't be established.
ECDSA key fingerprint is SHA256:vYTrXPg9BQCHyyApRJ37Zm363/2BLsU0Di5dWsK1oIo.
ECDSA key fingerprint is MD5:1d:b0:8b:12:eb:11:b0:49:bb:5b:c3:4d:61:12:5a:dd.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.168.41' (ECDSA) to the list of known hosts.
Red Hat Enterprise Linux CoreOS 43.81.202002032142.0
Part of OpenShift 4.3, RHCOS is a Kubernetes native operating system
managed by the Machine Config Operator (`clusteroperator/machine-config`).
WARNING: Direct SSH access to machines is not recommended; instead,
make configuration changes via `machineconfig` objects:
https://docs.openshift.com/container-platform/4.3/architecture/architecture-rhcos.html
---
[core@perflab-f8n55-worker-gpu-jbx27 ~]$ uptime
11:33:30 up 5 min, 1 user, load average: 0.57, 0.42, 0.21
[core@perflab-f8n55-worker-gpu-jbx27 ~]$ lspci -nn |grep -i nvidia
00:05.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] [10de:1db4] (rev a1)
The GPU machineset is available:
(overcloud) [stack@perflab-director ~]$ oc -n openshift-machine-api get machines | grep gpu
perflab-f8n55-worker-gpu-jbx27 Running m1-gpu.large regionOne nova 9m1s
(overcloud) [stack@perflab-director ~]$ oc get nodes perflab-f8n55-worker-gpu-jbx27 -o json | jq .metadata.labels
{
"node.openshift.io/os_id": "rhcos",
"node-role.kubernetes.io/worker": "",
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/instance-type": "m1-gpu.large",
"beta.kubernetes.io/os": "linux",
"failure-domain.beta.kubernetes.io/region": "regionOne",
"failure-domain.beta.kubernetes.io/zone": "nova",
"kubernetes.io/arch": "amd64",
"kubernetes.io/hostname": "perflab-f8n55-worker-gpu-jbx27",
"kubernetes.io/os": "linux"
}
Entitled builds
Search your system:

First click on “System”:

Go on the tab “Subscriptions”: https://access.redhat.com/management/systems

Download the certificate “abcdefg-hijkl-mnopq-rstu-vwxyz_certificates.zip” (ID changed, use your own ID).
[stack@perflab-director openshift]$ unzip abcdefg-hijkl-mnopq-rstu-vwxyz_certificates.zip
Archive: abcdefg-hijkl-mnopq-rstu-vwxyz_certificates.zip
signed Candlepin export for abcdefg-hijkl-mnopq-rstu-vwxyz
inflating: consumer_export.zip
inflating: signature
[stack@perflab-director openshift]$ unzip consumer_export.zip
Archive: consumer_export.zip
Candlepin export for abcdefg-hijkl-mnopq-rstu-vwxyz
inflating: export/meta.json
inflating: export/entitlement_certificates/01010101010101010.pem
stack@perflab-director openshift]$ ls export/entitlement_certificates/01010101010101010.pem
01010101010101010.pem
[stack@perflab-director openshift]$ cat export/entitlement_certificates/01010101010101010.pem
-----BEGIN CERTIFICATE-----
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
-----END CERTIFICATE-----
-----BEGIN ENTITLEMENT DATA----
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
-----END ENTITLEMENT DATA-----
-----BEGIN RSA SIGNATURE-----
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
-----END RSA SIGNATURE-----
-----BEGIN RSA PRIVATE KEY-----
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
-----END RSA PRIVATE KEY-----
Check mc status before:
[egallen@datastation crc-linux-1.6.0-amd64]$ oc get mc
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED
00-master 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
00-worker 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
01-master-container-runtime 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
01-master-kubelet 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
01-worker-container-runtime 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
01-worker-kubelet 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
99-master-e066c785-bb70-42fc-b758-5a414c7bcd8e-registries 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
99-master-ssh 2.2.0 21d
99-worker-f850b088-938e-4b3d-814a-adab854ba100-registries 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
99-worker-ssh 2.2.0 21d
rendered-master-03acbbe4bf880b01593c74b01927cf53 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
rendered-worker-e7d5c5648a26693356c167109e479099 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 21d
Download these two yaml:
[egallen@datastation crc-linux-1.6.0-amd64]$ wget https://raw.githubusercontent.com/openshift-psap/blog-artifacts/master/how-to-use-entitled-builds-with-ubi/0003-cluster-wide-machineconfigs.yaml.template
[egallen@datastation crc-linux-1.6.0-amd64]$ wget https://raw.githubusercontent.com/openshift-psap/blog-artifacts/master/how-to-use-entitled-builds-with-ubi/0004-cluster-wide-entitled-pod.yaml
[stack@perflab-director openshift]$ sed "s/BASE64_ENCODED_PEM_FILE/$(base64 -w 0 944900454599908294.pem)/g" 0003-cluster-wide-machineconfigs.yaml.template > 0003-cluster-wide-machineconfigs.yaml
(overcloud) [stack@perflab-director openshift]$ base64 export/entitlement_certificates/01010101010101010.pem
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
XxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
(overcloud) [stack@perflab-director openshift]$ oc create -f 0003-cluster-wide-machineconfigs.yaml
machineconfig.machineconfiguration.openshift.io/50-rhsm-conf created
machineconfig.machineconfiguration.openshift.io/50-entitlement-pem created
machineconfig.machineconfiguration.openshift.io/50-entitlement-key-pem created
If your cert file is big, you will have this error “/usr/bin/sed: Argument list too long” if you want to do a simple sed.
Install YAML Perl:
[egallen@datastation crc-linux-1.6.0-amd64]$ sudo dnf install perl-YAML
cp 0003-cluster-wide-machineconfigs.yaml.template 0003-cluster-wide-machineconfigs.yaml sed -i ‘/BASE64_ENCODED_PEM_FILE/r 944900454599908294_base64.pem’ 0003-cluster-wide-machineconfigs.yaml sed -i ‘:a;N;$!ba;s/BASE64_ENCODED_PEM_FILE\n//g’ 0003-cluster-wide-machineconfigs.yaml
Check the oc machine config status:
(overcloud) [stack@perflab-director openshift]$ oc get mc
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED
00-master 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
00-worker 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
01-master-container-runtime 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
01-master-kubelet 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
01-worker-container-runtime 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
01-worker-kubelet 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
50-entitlement-key-pem 2.2.0 65s
50-entitlement-pem 2.2.0 65s
50-rhsm-conf 2.2.0 65s
99-master-493d8245-d45a-4575-b421-1e3c49e383e9-registries 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
99-master-ssh 2.2.0 95m
99-worker-06e519f9-3a5b-4a7e-b306-664c0a4dd1ce-registries 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
99-worker-ssh 2.2.0 95m
rendered-master-3b612c987c792f3f57369dbe68617f7e 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
rendered-worker-0511a8c3cf81d041b1ecfe61ef504f11 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 60s
rendered-worker-17060e963227cc0287f88aa74ad1bd7c 25bb6aeb58135c38a667e849edf5244871be4992 2.2.0 93m
Check the status:
(overcloud) [stack@perflab-director openshift]$ oc create -f 0004-cluster-wide-entitled-pod.yaml
pod/cluster-entitled-build-pod created
(overcloud) [stack@perflab-director openshift]$ oc get pods
NAME READY STATUS RESTARTS AGE
cluster-entitled-build-pod 0/1 ContainerCreating 0 10s
(overcloud) [stack@perflab-director openshift]$ oc get pods
NAME READY STATUS RESTARTS AGE
cluster-entitled-build-pod 1/1 Running 0 24s
(overcloud) [stack@perflab-director openshift]$ oc logs cluster-entitled-build-pod | grep kernel-devel | tail -n 1
kernel-devel-4.18.0-147.5.1.el8_1.x86_64 : Development package for building
(overcloud) [stack@perflab-director openshift]$ cp 0003-cluster-wide-machineconfigs.yaml.template 0003-cluster-wide-machineconfigs.yaml
(overcloud) [stack@perflab-director openshift]$ sed -i '/BASE64_ENCODED_PEM_FILE/r 944900454599908294_base64.pem' 0003-cluster-wide-machineconfigs.yaml
(overcloud) [stack@perflab-director openshift]$ sed -i ':a;N;$!ba;s/BASE64_ENCODED_PEM_FILE\n//g' 0003-cluster-wide-machineconfigs.yaml
Success the cluster is entitled:
(overcloud) [stack@perflab-director openshift]$ oc logs cluster-entitled-build-pod
Updating Subscription Management repositories.
Unable to read consumer identity
Subscription Manager is operating in container mode.
Red Hat Enterprise Linux 8 for x86_64 - AppStre 5.5 MB/s | 14 MB 00:02
Red Hat Enterprise Linux 8 for x86_64 - BaseOS 6.3 MB/s | 14 MB 00:02
Red Hat Universal Base Image 8 (RPMs) - BaseOS 330 kB/s | 760 kB 00:02
Red Hat Universal Base Image 8 (RPMs) - AppStre 276 kB/s | 3.3 MB 00:12
Red Hat Universal Base Image 8 (RPMs) - CodeRea 8.8 kB/s | 9.1 kB 00:01
====================== Name Exactly Matched: kernel-devel ======================
kernel-devel-4.18.0-80.1.2.el8_0.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-80.el8.x86_64 : Development package for building kernel
: modules to match the kernel
kernel-devel-4.18.0-80.4.2.el8_0.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-80.7.1.el8_0.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-80.11.1.el8_0.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-147.el8.x86_64 : Development package for building kernel
: modules to match the kernel
kernel-devel-4.18.0-80.11.2.el8_0.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-80.7.2.el8_0.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-147.0.3.el8_1.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-147.0.2.el8_1.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-147.3.1.el8_1.x86_64 : Development package for building
: kernel modules to match the kernel
kernel-devel-4.18.0-147.5.1.el8_1.x86_64 : Development package for building
: kernel modules to match the kernel
These 3 files are created:
- /etc/rhsm/rhsm.conf
- /etc/pki/entitlement/entitlement.pem
- /etc/pki/entitlement/entitlement-key.pem
[core@perflab-f8n55-worker-gpu-jbx27 ~]$ ls -la /etc/rhsm/rhsm.conf /etc/pki/entitlement/entitlement.pem /etc/pki/entitlement/entitlement-key.pem
-rw-r--r--. 1 root root 140277 Feb 14 12:15 /etc/pki/entitlement/entitlement-key.pem
-rw-r--r--. 1 root root 140277 Feb 14 12:15 /etc/pki/entitlement/entitlement.pem
-rw-r--r--. 1 root root 2851 Feb 14 12:15 /etc/rhsm/rhsm.conf
Deploy the Node Feature Discovery Operator
The Node Feature Discovery Operator identifies hardware device features in nodes.
Because of this bug:
https://bugzilla.redhat.com/show_bug.cgi?id=1789560
we will not use the OpenShift console
[stack@perflab-director openshift]$ git clone https://github.com/openshift/cluster-nfd-operator
Cloning into 'cluster-nfd-operator'...
remote: Enumerating objects: 17531, done.
remote: Total 17531 (delta 0), reused 0 (delta 0), pack-reused 17531
Receiving objects: 100% (17531/17531), 22.74 MiB | 3.58 MiB/s, done.
Resolving deltas: 100% (7097/7097), done.
[stack@perflab-director openshift]$ cd cluster-nfd-operator
Deploy the NFD Operator:
[stack@perflab-director cluster-nfd-operator]$ make deploy
customresourcedefinition.apiextensions.k8s.io/nodefeaturediscoveries.nfd.openshift.io created
sleep 1
for obj in manifests/0100_namespace.yaml manifests/0200_service_account.yaml manifests/0300_cluster_role.yaml manifests/0400_cluster_role_binding.yaml manifests/0600_operator.yaml; do \
sed 's+REPLACE_IMAGE+quay.io/zvonkok/cluster-nfd-operator:master+g; s+REPLACE_NAMESPACE+openshift-operators+g; s+IfNotPresent+IfNotPresent+' $obj | kubectl apply -f - ;\
sleep 1;\
done
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
namespace/openshift-operators configured
serviceaccount/nfd-operator created
clusterrole.rbac.authorization.k8s.io/nfd-operator created
clusterrolebinding.rbac.authorization.k8s.io/nfd-operator created
deployment.apps/nfd-operator created
nodefeaturediscovery.nfd.openshift.io/nfd-master-server created
(overcloud) [stack@perflab-director cluster-nfd-operator]$ oc get pods -n openshift-nfd
NAME READY STATUS RESTARTS AGE
nfd-master-hp8cb 1/1 Running 0 24s
nfd-master-vf7nd 0/1 ContainerCreating 0 24s
nfd-master-zt6r9 0/1 ContainerCreating 0 24s
nfd-operator-5f47ccf496-sbsck 1/1 Running 0 54s
nfd-worker-84j5s 1/1 Running 1 24s
nfd-worker-ch9nc 1/1 Running 1 24s
nfd-worker-mdnwb 1/1 Running 1 24s
nfd-worker-pwfdf 1/1 Running 1 24s
[stack@perflab-director openshift]$ oc get pods -n openshift-nfd
NAME READY STATUS RESTARTS AGE
nfd-master-m8mzx 1/1 Running 0 99s
nfd-master-tlv2w 1/1 Running 0 99s
nfd-master-x68jx 1/1 Running 0 99s
nfd-operator-5f47ccf496-zpqln 1/1 Running 0 2m6s
nfd-worker-2pgxr 1/1 Running 2 100s
nfd-worker-f8mjs 1/1 Running 2 100s
nfd-worker-ktnp9 1/1 Running 2 100s
nfd-worker-wcttc 1/1 Running 2 100s
[stack@perflab-director cluster-nfd-operator]$ oc describe node perflab-dtlt8-worker-gpu-clw5x |grep 10de
feature.node.kubernetes.io/pci-10de.present=true
[stack@perflab-director ~]$ oc describe node perflab-dtlt8-worker-gpu-clw5x| egrep 'Roles|pci'
Roles: worker
feature.node.kubernetes.io/pci-1013.present=true
feature.node.kubernetes.io/pci-10de.present=true
feature.node.kubernetes.io/pci-1af4.present=true
Deploy the GPU Operator
The GPU Operator manages NVIDIA GPU resources in a Kubernetes cluster and automates tasks related to bootstrapping GPU nodes.
We will apply this gpu-operator procedure: https://nvidia.github.io/gpu-operator/
Download the Helm binary:
[stack@perflab-director ~]$ cd /usr/local/bin/
[stack@perflab-director bin]$ sudo curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-amd64 -o /usr/local/bin/helm
[stack@perflab-director bin]$ sudo chmod 755 helm
Check helm version:
[stack@perflab-director ~]$ helm version
version.BuildInfo{Version:"v3.0", GitCommit:"b31719aab7963acf4887a1c1e6d5e53378e34d93", GitTreeState:"clean", GoVersion:"go1.13.4"}
Add the NVIDIA repo to helm:
[stack@perflab-director ~]$ helm repo add nvidia https://nvidia.github.io/gpu-operator
"nvidia" has been added to your repositories
Update helm repositories:
[stack@perflab-director ~]$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "nvidia" chart repository
Update Complete. ⎈ Happy Helming!⎈
Install the GPU Operator:
(overcloud) [stack@perflab-director ~]$ helm install --devel https://nvidia.github.io/gpu-operator/gpu-operator-1.0.0-beta.0.tgz --set platform.openshift=true,operator.defaultRuntime=crio,nfd.enabled=false -n openshift-operators --generate-name --wait
NAME: gpu-operator-1-1581685469
LAST DEPLOYED: Fri Feb 14 08:04:29 2020
NAMESPACE: openshift-operators
STATUS: deployed
REVISION: 1
TEST SUITE: None
(overcloud)
The installation of the GPU Operator is completed:
(overcloud) [stack@perflab-director ~]$ oc get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
special-resource-operator-84b85565d7-pqfdj 1/1 Running 0 51s
(overcloud) [stack@perflab-director ~]$ oc get pods -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-mt85t 1/1 Running 0 2m38s
nvidia-driver-daemonset-7vn8q 1/1 Running 0 2m28s
nvidia-driver-validation 1/1 Running 0 2m13s
(overcloud) [stack@perflab-director ~]$ oc describe pod nvidia-driver-daemonset-7vn8q -n gpu-operator-resources
Name: nvidia-driver-daemonset-7vn8q
Namespace: gpu-operator-resources
Priority: 0
Node: perflab-f8n55-worker-gpu-jbx27/10.0.0.28
Start Time: Fri, 14 Feb 2020 07:38:33 -0500
Labels: app=nvidia-driver-daemonset
controller-revision-hash=677dc994bd
pod-template-generation=1
Annotations: k8s.v1.cni.cncf.io/networks-status:
[{
"name": "openshift-sdn",
"interface": "eth0",
"ips": [
"10.130.2.8"
],
"dns": {},
"default-route": [
"10.130.2.1"
]
}]
openshift.io/scc: nvidia-driver
scheduler.alpha.kubernetes.io/critical-pod:
Status: Running
IP: 10.130.2.8
IPs:
IP: 10.130.2.8
Controlled By: DaemonSet/nvidia-driver-daemonset
Containers:
nvidia-driver-ctr:
Container ID: cri-o://f31bb7c26e2e3daaea958ac99835807c563b612904b2c1f8e8753b5a4a6da676
Image: nvidia/driver:440.33.01-rhcos4.3
Image ID: docker.io/nvidia/driver@sha256:5f8a16647d6e15f5fe79aa38c6c7f9793762d1c7fae0a0a96f572018439b78a5
Port: <none>
Host Port: <none>
Command:
nvidia-driver
Args:
init
State: Running
Started: Fri, 14 Feb 2020 07:38:47 -0500
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/etc/containers/oci/hooks.d from config (rw)
/run/nvidia from run-nvidia (rw)
/var/run/secrets/kubernetes.io/serviceaccount from nvidia-driver-token-6kxv5 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
run-nvidia:
Type: HostPath (bare host directory volume)
Path: /run/nvidia
HostPathType:
config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: nvidia-driver
Optional: false
nvidia-driver-token-6kxv5:
Type: Secret (a volume populated by a Secret)
SecretName: nvidia-driver-token-6kxv5
Optional: false
QoS Class: BestEffort
Node-Selectors: feature.node.kubernetes.io/kernel-version.full=4.18.0-147.3.1.el8_1.x86_64
feature.node.kubernetes.io/pci-10de.present=true
Tolerations: node.kubernetes.io/disk-pressure:NoSchedule
node.kubernetes.io/memory-pressure:NoSchedule
node.kubernetes.io/not-ready:NoExecute
node.kubernetes.io/pid-pressure:NoSchedule
node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unschedulable:NoSchedule
nvidia.com/gpu:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned gpu-operator-resources/nvidia-driver-daemonset-7vn8q to perflab-f8n55-worker-gpu-jbx27
Normal Pulling 2m49s kubelet, perflab-f8n55-worker-gpu-jbx27 Pulling image "nvidia/driver:440.33.01-rhcos4.3"
Normal Pulled 2m44s kubelet, perflab-f8n55-worker-gpu-jbx27 Successfully pulled image "nvidia/driver:440.33.01-rhcos4.3"
Normal Created 2m44s kubelet, perflab-f8n55-worker-gpu-jbx27 Created container nvidia-driver-ctr
Normal Started 2m43s kubelet, perflab-f8n55-worker-gpu-jbx27 Started container nvidia-driver-ctr
We can describe the Special Resource Operator:
(overcloud) [stack@perflab-director ~]$ oc describe specialresources --all-namespaces
Name: gpu
Namespace: gpu-operator-resources
Labels: <none>
Annotations: <none>
API Version: sro.openshift.io/v1alpha1
Kind: SpecialResource
Metadata:
Creation Timestamp: 2020-02-14T12:38:23Z
Generation: 1
Resource Version: 49379
Self Link: /apis/sro.openshift.io/v1alpha1/namespaces/gpu-operator-resources/specialresources/gpu
UID: 03946227-8c52-44cd-9eb7-5e5fa07afa5a
Spec:
Priority Classes: <nil>
Scheduling Type: none
Events: <none>
Helm is deployed:
(overcloud) [stack@perflab-director ~]$ helm ls --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gpu-operator-1-1581683893 openshift-operators 1 2020-02-14 07:38:14.088459187 -0500 EST deployed gpu-operator-1.0.0-beta.0 1.0.0-beta.0
(overcloud) [stack@perflab-director ~]$ oc get ds --all-namespaces
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
gpu-operator-resources nvidia-container-toolkit-daemonset 1 1 1 1 1 feature.node.kubernetes.io/pci-10de.present=true 4m13s
gpu-operator-resources nvidia-driver-daemonset 1 1 1 1 1 feature.node.kubernetes.io/kernel-version.full=4.18.0-147.3.1.el8_1.x86_64,feature.node.kubernetes.io/pci-10de.present=true 4m3s
node-feature-discovery nfd-master 3 3 3 3 3 node-role.kubernetes.io/master= 4m22s
node-feature-discovery nfd-worker 4 4 4 4 4 <none> 4m22s
openshift-apiserver apiserver 3 3 3 3 3 node-role.kubernetes.io/master= 120m
openshift-cluster-node-tuning-operator tuned 7 7 7 7 7 kubernetes.io/os=linux 116m
openshift-controller-manager controller-manager 3 3 3 3 3 node-role.kubernetes.io/master= 123m
openshift-dns dns-default 7 7 7 7 7 kubernetes.io/os=linux 122m
openshift-image-registry node-ca 7 7 7 7 7 kubernetes.io/os=linux 116m
openshift-machine-config-operator machine-config-daemon 7 7 7 7 7 kubernetes.io/os=linux 123m
openshift-machine-config-operator machine-config-server 3 3 3 3 3 node-role.kubernetes.io/master= 122m
openshift-monitoring node-exporter 7 7 7 7 7 kubernetes.io/os=linux 116m
openshift-multus multus 7 7 7 7 7 kubernetes.io/os=linux 125m
openshift-multus multus-admission-controller 3 3 3 3 3 node-role.kubernetes.io/master= 125m
openshift-sdn ovs 7 7 7 7 7 kubernetes.io/os=linux 125m
openshift-sdn sdn 7 7 7 7 7 kubernetes.io/os=linux 125m
openshift-sdn sdn-controller 3 3 3 3 3 node-role.kubernetes.io/master= 125m
Temporary driver fix workaround
If your GPU Operator deployment is blocked at step 3 “nvidia-driver-validation”:
[stack@perflab-director ~]$ oc get pod -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-pqdd9 1/1 Running 0 53m
nvidia-driver-daemonset-p8dkp 1/1 Running 0 53m
nvidia-driver-validation 0/1 Error 8 53m
[stack@perflab-director ~]$ oc logs nvidia-driver-validation -n gpu-operator-resources
...
In file included from cudaNvSci.cpp:28:
cudaNvSci.h:33:10: fatal error: nvscibuf.h: No such file or directory
...
In file included from main.cpp:30:
cudaNvSci.h:33:10: fatal error: nvscibuf.h: No such file or directory
...
make: Target 'all' not remade because of errors.
checkCudaErrors() Driver API error = 0003 "CUDA_ERROR_NOT_INITIALIZED" from file <../../Common/helper_cuda_drvapi.h>, line 229.
NVIDIA containers are contained and not privileged with an SELinux policy. The policy creates a new SELinux type: nvidia_container_t with which the container should run.
The used SELinux type “container_runtime_tmpfs_t” is not correct because of a bug with this beta code;
[stack@perflab-director ~]$ oc exec -it nvidia-driver-daemonset-p8dkp bash -n gpu-operator-resources
[root@nvidia-driver-daemonset-p8dkp dev]# ls -Z /dev/nvidia*
system_u:object_r:container_runtime_tmpfs_t:s0 /dev/nvidia-modeset system_u:object_r:container_runtime_tmpfs_t:s0 /dev/nvidia-uvm-tools system_u:object_r:container_runtime_tmpfs_t:s0 /dev/nvidiactl
system_u:object_r:container_runtime_tmpfs_t:s0 /dev/nvidia-uvm system_u:object_r:container_runtime_tmpfs_t:s0 /dev/nvidia0
Fix the SELinux type:
[root@nvidia-driver-daemonset-p8dkp dev]# chcon -t container_file_t /dev/nvidia*
Update the pod:
[stack@perflab-director ~]$ oc get pod nvidia-driver-validation -o yaml -n gpu-operator-resources | oc replace --force -f -
pod "nvidia-driver-validation" deleted
pod/nvidia-driver-validation replaced
Check again the SELinux context, “container_runtime_tmpfs_t” is replaced by “container_file_t”:
[stack@perflab-director ~]$ oc exec -it nvidia-driver-daemonset-p8dkp bash -n gpu-operator-resources
[root@nvidia-driver-daemonset-p8dkp nvidia-440.33.01]# ls -Z /dev/nvidia*
system_u:object_r:container_file_t:s0 /dev/nvidia-modeset system_u:object_r:container_file_t:s0 /dev/nvidia0
system_u:object_r:container_file_t:s0 /dev/nvidia-uvm system_u:object_r:container_file_t:s0 /dev/nvidiactl
system_u:object_r:container_file_t:s0 /dev/nvidia-uvm-tools
Check the status of the GPU Operator installation:
[stack@perflab-director ~]$ oc logs nvidia-driver-validation -n gpu-operator-resources
...
Transaction Summary
================================================================================
Install 4 Packages
Upgrade 16 Packages
Total download size: 23 M
Downloading Packages:
(1/20): diffutils-3.6-5.el8.x86_64.rpm 217 kB/s | 359 kB 00:01
(2/20): glibc-langpack-en-2.28-72.el8_1.1.x86_6 462 kB/s | 818 kB 00:01
(3/20): xkeyboard-config-2.24-3.el8.noarch.rpm 461 kB/s | 828 kB 00:01
...
Success, validation is passed:
[stack@perflab-director ~]$ oc get pod -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-pqdd9 1/1 Running 0 66m
nvidia-device-plugin-daemonset-vv69w 0/1 ContainerCreating 0 7s
nvidia-driver-daemonset-p8dkp 1/1 Running 0 66m
nvidia-driver-validation 0/1 Completed 0 5m
GPU Operator installation is completed:
[stack@perflab-director ~]$ oc get pod -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-pqdd9 1/1 Running 0 67m
nvidia-device-plugin-daemonset-vv69w 1/1 Running 0 48s
nvidia-device-plugin-validation 1/1 Running 0 29s
nvidia-driver-daemonset-p8dkp 1/1 Running 0 67m
nvidia-driver-validation 0/1 Completed 0 5m41s
[stack@perflab-director ~]$ oc describe node perflab-f8n55-worker-gpu-jbx27 | grep nvidia
nvidia.com/gpu: 1
nvidia.com/gpu: 1
gpu-operator-resources nvidia-container-toolkit-daemonset-pqdd9 0 (0%) 0 (0%) 0 (0%) 0 (0%) 68m
gpu-operator-resources nvidia-device-plugin-daemonset-vv69w 0 (0%) 0 (0%) 0 (0%) 0 (0%) 112s
gpu-operator-resources nvidia-device-plugin-validation 0 (0%) 0 (0%) 0 (0%) 0 (0%) 93s
gpu-operator-resources nvidia-driver-daemonset-p8dkp 0 (0%) 0 (0%) 0 (0%) 0 (0%) 68m
nvidia.com/gpu 1 1
(overcloud) [stack@perflab-director ~]$ oc apply -f https://raw.githubusercontent.com/NVIDIA/gpu-operator/master/manifests/cr/sro_cr_sched_none.yaml
Warning: oc apply should be used on resource created by either oc create --save-config or oc apply
specialresource.sro.openshift.io/gpu configured
If you need to remove the GPU Operator, get the helm name with the command:
[stack@perflab-director openshift]$ helm ls --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gpu-operator-1-1581453942 openshift-operators 1 2020-02-11 15:45:42.70687391 -0500 EST deployed gpu-operator-1.0.0-techpreview.8 1.0.0-techpreview.8
If needed, you can uninstall the GPU Operator with this command (the node must be rebooted after this operation):
WARNING$ helm uninstall -n openshift-operators gpu-operator-1-1581453942
release "gpu-operator-1-1581453942" uninstalled
Test TensorFlow Notebook GPU
[stack@perflab-director ~]$ oc apply -f https://nvidia.github.io/gpu-operator/notebook-example.yml
service/tf-notebook created
pod/tf-notebook created
[stack@perflab-director ~]$ oc get pods
NAME READY STATUS RESTARTS AGE
tf-notebook 1/1 Running 0 19s
[stack@perflab-director ~]$ oc logs tf-notebook
Execute the command
[I 10:41:08.664 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret
[W 10:41:09.160 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using encryption. This is not recommended.
[I 10:41:09.250 NotebookApp] import tensorboard error, check tensorflow install
[I 10:41:09.250 NotebookApp] jupyter_tensorboard extension loaded.
[I 10:41:09.286 NotebookApp] JupyterLab alpha preview extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
JupyterLab v0.24.1
Known labextensions:
[I 10:41:09.288 NotebookApp] Running the core application with no additional extensions or settings
[I 10:41:09.292 NotebookApp] Serving notebooks from local directory: /home/jovyan
[I 10:41:09.292 NotebookApp] 0 active kernels
[I 10:41:09.292 NotebookApp] The Jupyter Notebook is running at: http://[all ip addresses on your system]:8888/?token=173a089e863cabc261b25ea3ebfbd47111311e0f86a6948c
[I 10:41:09.292 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 10:41:09.292 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=XXXXXXXX
[stack@perflab-director ~]$ oc port-forward tf-notebook 8888:8888
Forwarding from 127.0.0.1:8888 -> 8888
Forwarding from [::1]:8888 -> 8888
Handling connection for 8888
If you don’t have the oc client on your laptop, tou can create a ssh tunnel:
egallen@laptop ~ % ssh -N -L 8888:localhost:8888 perflab-director
Take your token printed by the previous “oc logs tf-notebook” command and and connect to this URL http://localhost:8888 with your latop browser:

Create a new terminal:

Check the NVIDIA driver status with the NVIDIA System Management Interface command line utility:

Test nvidia-smi pod
Create a nvidia-smi pod definition YAML file:
(overcloud) [stack@perflab-director openshift]$ cat << EOF > nvidia-smi.yaml
apiVersion: v1
kind: Pod
metadata:
name: nvidia-smi
spec:
containers:
- image: nvidia/cuda
name: nvidia-smi
command: [ nvidia-smi ]
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
EOF
Create the nvidia-smi pod:
(overcloud) [stack@perflab-director openshift]$ oc create -f nvidia-smi.yaml
pod/nvidia-smi created
(overcloud) [stack@perflab-director openshift]$ oc get pods
NAME READY STATUS RESTARTS AGE
nvidia-smi 0/1 ContainerCreating 0 5s
(overcloud) [stack@perflab-director openshift]$ oc get pods
NAME READY STATUS RESTARTS AGE
nvidia-smi 0/1 Completed 0 15s
Success, the NVIDIA drivers are available in the pod:
[stack@perflab-director ~]$ oc logs nvidia-smi
Fri Feb 14 14:25:01 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:00:05.0 Off | Off |
| N/A 29C P0 24W / 250W | 0MiB / 16160MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Delete the nvidia-smi pod:
(overcloud) [stack@perflab-director openshift]$ oc delete pod nvidia-smi
pod "nvidia-smi" deleted
TensorFlow benchmarks with GPU
Create the GPU benchmark Pod Definition YAML file:
(overcloud) [stack@perflab-director pods]$ cat << EOF > tensorflow-benchmarks-gpu.yaml
apiVersion: v1
kind: Pod
metadata:
name: tensorflow-benchmarks-gpu
spec:
containers:
- image: nvcr.io/nvidia/tensorflow:19.09-py3
name: cudnn
command: ["/bin/sh","-c"]
args: ["git clone https://github.com/tensorflow/benchmarks.git;cd benchmarks/scripts/tf_cnn_benchmarks;python3 tf_cnn_benchmarks.py --num_gpus=1 --data_format=NHWC --batch_size=32 --model=resnet50 --variable_update=parameter_server"]
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
EOF
Create the GPU benchmark pod:
[stack@perflab-director openshift]$ oc create -f tensorflow-benchmarks-gpu.yaml
pod/tensorflow-benchmarks-gpu created
The pod switch to “Completed” status after 30 seconds:
(overcloud) [stack@perflab-director pods]$ oc get pod
NAME READY STATUS RESTARTS AGE
tensorflow-benchmarks-gpu 0/1 Completed 0 30s
Check the GPU benchark results, the training is fast with 325.03 images/sec:
[stack@perflab-director openshift]$ oc get pods
NAME READY STATUS RESTARTS AGE
tensorflow-benchmarks-gpu 0/1 ContainerCreating 0 2m31s
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Error from server (BadRequest): container "cudnn" in pod "tensorflow-benchmarks-gpu" is waiting to start: ContainerCreating
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-gpu
Cloning into 'benchmarks'...
2020-02-14 16:54:23.102462: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.1
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/compat/v2_compat.py:61: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
2020-02-14 16:54:25.547605: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2194840000 Hz
2020-02-14 16:54:25.548401: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x6147240 executing computations on platform Host. Devices:
2020-02-14 16:54:25.548424: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): <undefined>, <undefined>
2020-02-14 16:54:25.551216: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcuda.so.1
2020-02-14 16:54:25.738780: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:25.739634: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x614d500 executing computations on platform CUDA. Devices:
2020-02-14 16:54:25.739673: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Tesla V100-PCIE-16GB, Compute Capability 7.0
2020-02-14 16:54:25.739944: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:25.740598: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties:
name: Tesla V100-PCIE-16GB major: 7 minor: 0 memoryClockRate(GHz): 1.38
pciBusID: 0000:00:05.0
2020-02-14 16:54:25.740633: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.1
2020-02-14 16:54:25.742891: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10
2020-02-14 16:54:25.745017: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcufft.so.10
2020-02-14 16:54:25.745895: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcurand.so.10
2020-02-14 16:54:25.748212: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcusolver.so.10
2020-02-14 16:54:25.749555: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcusparse.so.10
2020-02-14 16:54:25.754862: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7
2020-02-14 16:54:25.755083: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:25.755830: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:25.756468: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0
2020-02-14 16:54:25.756512: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.1
2020-02-14 16:54:26.299469: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-02-14 16:54:26.299532: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0
2020-02-14 16:54:26.299540: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N
2020-02-14 16:54:26.299830: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:26.300595: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:26.301273: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14959 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-16GB, pci bus id: 0000:00:05.0, compute capability: 7.0)
WARNING:tensorflow:From /workspace/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:134: conv2d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv2D` instead.
W0214 16:54:26.322175 140651336546112 deprecation.py:323] From /workspace/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:134: conv2d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv2D` instead.
WARNING:tensorflow:From /workspace/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:266: max_pooling2d (from tensorflow.python.layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.MaxPooling2D instead.
W0214 16:54:26.670282 140651336546112 deprecation.py:323] From /workspace/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:266: max_pooling2d (from tensorflow.python.layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.MaxPooling2D instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/losses/losses_impl.py:121: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
W0214 16:54:29.124635 140651336546112 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/losses/losses_impl.py:121: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
WARNING:tensorflow:From /workspace/benchmarks/scripts/tf_cnn_benchmarks/benchmark_cnn.py:2267: Supervisor.__init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.MonitoredTrainingSession
W0214 16:54:30.438534 140651336546112 deprecation.py:323] From /workspace/benchmarks/scripts/tf_cnn_benchmarks/benchmark_cnn.py:2267: Supervisor.__init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.MonitoredTrainingSession
2020-02-14 16:54:30.891211: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:30.892045: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties:
name: Tesla V100-PCIE-16GB major: 7 minor: 0 memoryClockRate(GHz): 1.38
pciBusID: 0000:00:05.0
2020-02-14 16:54:30.892100: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.1
2020-02-14 16:54:30.892144: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10
2020-02-14 16:54:30.892165: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcufft.so.10
2020-02-14 16:54:30.892177: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcurand.so.10
2020-02-14 16:54:30.892188: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcusolver.so.10
2020-02-14 16:54:30.892199: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcusparse.so.10
2020-02-14 16:54:30.892211: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7
2020-02-14 16:54:30.892302: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:30.893064: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:30.893686: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0
2020-02-14 16:54:30.893715: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-02-14 16:54:30.893723: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0
2020-02-14 16:54:30.893729: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N
2020-02-14 16:54:30.893824: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:30.894593: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-02-14 16:54:30.895245: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14959 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-16GB, pci bus id: 0000:00:05.0, compute capability: 7.0)
2020-02-14 16:54:31.635562: W tensorflow/compiler/jit/mark_for_compilation_pass.cc:1412] (One-time warning): Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile.
INFO:tensorflow:Running local_init_op.
I0214 16:54:32.003238 140651336546112 session_manager.py:500] Running local_init_op.
INFO:tensorflow:Done running local_init_op.
I0214 16:54:32.102240 140651336546112 session_manager.py:502] Done running local_init_op.
2020-02-14 16:54:34.303587: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10
2020-02-14 16:54:34.694265: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7
TensorFlow: 1.14
Model: resnet50
Dataset: imagenet (synthetic)
Mode: training
SingleSess: False
Batch size: 32 global
32 per device
Num batches: 100
Num epochs: 0.00
Devices: ['/gpu:0']
NUMA bind: False
Data format: NHWC
Optimizer: sgd
Variables: parameter_server
==========
Generating training model
Initializing graph
Running warm up
Done warm up
Step Img/sec total_loss
1 images/sec: 324.6 +/- 0.0 (jitter = 0.0) 8.108
10 images/sec: 322.6 +/- 0.4 (jitter = 1.1) 8.122
20 images/sec: 323.6 +/- 0.5 (jitter = 2.0) 7.983
30 images/sec: 324.6 +/- 0.4 (jitter = 3.1) 7.780
40 images/sec: 324.9 +/- 0.3 (jitter = 2.4) 7.848
50 images/sec: 325.1 +/- 0.3 (jitter = 2.0) 7.779
60 images/sec: 324.6 +/- 0.3 (jitter = 2.8) 7.825
70 images/sec: 324.3 +/- 0.3 (jitter = 2.8) 7.839
80 images/sec: 324.3 +/- 0.3 (jitter = 2.8) 7.819
90 images/sec: 324.3 +/- 0.2 (jitter = 2.7) 7.647
100 images/sec: 324.5 +/- 0.2 (jitter = 2.8) 7.915
----------------------------------------------------------------
total images/sec: 324.24
----------------------------------------------------------------
Tensorflow benchmarks with CPU
To compare, create a CPU Pod Definition YAML file:
(overcloud) [stack@perflab-director pods]$ cat << EOF > tensorflow-benchmarks-cpu.yaml
apiVersion: v1
kind: Pod
metadata:
name: tensorflow-benchmarks-cpu
spec:
containers:
- image: nvcr.io/nvidia/tensorflow:19.09-py3
name: cudnn
command: ["/bin/sh","-c"]
args: ["git clone https://github.com/tensorflow/benchmarks.git;cd benchmarks/scripts/tf_cnn_benchmarks;python3 tf_cnn_benchmarks.py --device=cpu --data_format=NHWC --batch_size=32 --model=resnet50 --variable_update=parameter_server"]
restartPolicy: Never
EOF
Create the CPU benchmark pod:
(overcloud) [stack@perflab-director pods]$ oc create -f tensorflow-benchmarks-cpu.yaml
pod/tensorflow-benchmarks-cpu created
Because it takes a lot of time with CPU only, lets have a look in the container:
(overcloud) [stack@perflab-director pods]$ oc rsh tensorflow-benchmarks-cpu
(overcloud) [stack@perflab-director pods]$ top
top - 22:18:38 up 10:35, 0 users, load average: 6.07, 5.90, 5.10
Tasks: 5 total, 1 running, 4 sleeping, 0 stopped, 0 zombie
%Cpu0 : 85.9 us, 2.7 sy, 0.0 ni, 10.4 id, 0.0 wa, 1.0 hi, 0.0 si, 0.0 st
%Cpu1 : 86.7 us, 2.3 sy, 0.0 ni, 8.7 id, 0.0 wa, 1.0 hi, 1.3 si, 0.0 st
%Cpu2 : 87.9 us, 2.7 sy, 0.0 ni, 8.7 id, 0.0 wa, 0.7 hi, 0.0 si, 0.0 st
%Cpu3 : 85.3 us, 3.0 sy, 0.0 ni, 10.3 id, 0.0 wa, 1.0 hi, 0.3 si, 0.0 st
KiB Mem : 32936388 total, 5645924 free, 5718028 used, 21572436 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 26818208 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30 root 20 0 27.200g 4.241g 512752 S 342.7 13.5 89:00.66 tf_cnn_benchmar
1 root 20 0 20124 3588 3268 S 0.0 0.0 0:00.02 bash
40 root 20 0 32100 10952 5444 S 0.0 0.0 0:00.03 python3
386 root 20 0 23516 7076 3392 S 0.0 0.0 0:00.03 bash
693 root 20 0 40460 3460 2976 R 0.0 0.0 0:00.00 top
The pod switch to “Completed” status after 30 minutes:
[stack@perflab-director ~]$ oc get pods
NAME READY STATUS RESTARTS AGE
tensorflow-benchmarks-cpu 0/1 Completed 0 30m
Check the CPU benchark results, the training is slow with 2.24 images/sec:
[stack@perflab-director ~]$ oc logs tensorflow-benchmarks-cpu
TensorFlow: 1.14
Model: resnet50
Dataset: imagenet (synthetic)
Mode: training
SingleSess: False
Batch size: 32 global
32 per device
Num batches: 100
Num epochs: 0.00
Devices: ['/cpu:0']
NUMA bind: False
Data format: NHWC
Optimizer: sgd
Variables: parameter_server
==========
Generating training model
Initializing graph
Running warm up
Done warm up
Step Img/sec total_loss
1 images/sec: 2.2 +/- 0.0 (jitter = 0.0) 8.108
10 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 8.122
20 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.983
30 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.780
40 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.848
50 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.779
60 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.825
70 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.838
80 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.818
90 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.646
100 images/sec: 2.1 +/- 0.0 (jitter = 0.1) 7.913
----------------------------------------------------------------
total images/sec: 2.08
----------------------------------------------------------------
With this setup one pod can increase by 145 the resnet50 training performance with Red Hat OpenShift, Red Hat OpenStack Platform and NVIDIA GPU.
Configuring an HTPasswd identity provider
To configure the authentification and remove this warning banner in the console “You are logged in as a temporary administrative user. Update the cluster OAuth configuration to allow others to log in.”:

we will apply this documentation:
https://docs.openshift.com/container-platform/4.3/authentication/identity_providers/configuring-htpasswd-identity-provider.html
Create an htpasswd file to store the user and password information:
[stack@perflab-director ~]$ htpasswd -c -B -b egallen.htpasswd egallen MyPasswdXXXXXXXXXXXX
Adding password for user egallen
[stack@perflab-director ~]$ cat egallen.htpasswd
egallen:$2y$05$lHlIWyk9d7zjtcwgG9uFtOabzmvCURX1MsZYpaXCxEi1eQO92I6ku
Create HTPasswd Custom Resource:
[stack@perflab-director ~]$ cat << EOF > htpasswd-cr.yaml
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_htpasswd_provider
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret
EOF
Create an OpenShift Container Platform Secret that contains the htpasswd user file:
[stack@perflab-director ~]$ oc create secret generic htpass-secret --from-file=htpasswd=egallen.htpasswd -n openshift-config
secret/htpass-secret created
Apply the defined Custom Resource (you can safely ignore the warning):
[stack@perflab-director ~]$ oc apply -f htpasswd-cr.yaml
Warning: oc apply should be used on resource created by either oc create --save-config or oc apply
oauth.config.openshift.io/cluster configuredoc apply -f htpasswd-cr.yaml
Bind the cluster-admin role to the user ’egallen’:
[stack@perflab-director ~]$ oc adm policy add-cluster-role-to-user cluster-admin egallen
clusterrole.rbac.authorization.k8s.io/cluster-admin added: "egallen"
Try to login:
[stack@perflab-director ~]$ oc login -u egallen
Authentication required for https://api.perflab.lan.redhat.com:6443 (openshift)
Username: egallen
Password:
Login successful.
You don't have any projects. You can try to create a new project, by running
oc new-project <projectname>
Check “who you are”:
[stack@perflab-director ~]$ oc whoami
egallen
Unlog, choose the provider “my_htpasswd_provider”:

Add your credentials:

Success, you user is now a cluster admin:

MachineSet CPU worker scaling
Check the current status:
[stack@perflab-director ~]$ oc get machinesets -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
perflab-f8n55-worker 3 3 3 3 17d
perflab-f8n55-worker-gpu 1 1 1 1 17d
[stack@perflab-director ~]$ oc get nodes
NAME STATUS ROLES AGE VERSION
perflab-f8n55-master-0 Ready master 17d v1.16.2
perflab-f8n55-master-1 Ready master 17d v1.16.2
perflab-f8n55-master-2 Ready master 17d v1.16.2
perflab-f8n55-worker-5wk49 Ready worker 17d v1.16.2
perflab-f8n55-worker-bt9qk Ready worker 17d v1.16.2
perflab-f8n55-worker-gpu-jbx27 Ready worker 17d v1.16.2
perflab-f8n55-worker-hpfcl Ready worker 17d v1.16.2
[stack@perflab-director ~]$ oc get machine -n openshift-machine-api
NAME PHASE TYPE REGION ZONE AGE
perflab-f8n55-master-0 Running m1.large regionOne nova 17d
perflab-f8n55-master-1 Running m1.large regionOne nova 17d
perflab-f8n55-master-2 Running m1.large regionOne nova 17d
perflab-f8n55-worker-5wk49 Running m1.large regionOne nova 17d
perflab-f8n55-worker-bt9qk Running m1.large regionOne nova 17d
perflab-f8n55-worker-gpu-jbx27 Running m1-gpu.large regionOne nova 17d
perflab-f8n55-worker-hpfcl Running m1.large regionOne nova 17d
Get more details on one node:
[stack@perflab-director ~]$ oc get node perflab-f8n55-worker-5wk49 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
perflab-f8n55-worker-5wk49 Ready worker 17d v1.16.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m1.large,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=regionOne,failure-domain.beta.kubernetes.io/zone=nova,feature.node.kubernetes.io/cpu-cpuid.ADX=true,feature.node.kubernetes.io/cpu-cpuid.AESNI=true,feature.node.kubernetes.io/cpu-cpuid.AVX2=true,feature.node.kubernetes.io/cpu-cpuid.AVX512BW=true,feature.node.kubernetes.io/cpu-cpuid.AVX512CD=true,feature.node.kubernetes.io/cpu-cpuid.AVX512DQ=true,feature.node.kubernetes.io/cpu-cpuid.AVX512F=true,feature.node.kubernetes.io/cpu-cpuid.AVX512VL=true,feature.node.kubernetes.io/cpu-cpuid.AVX=true,feature.node.kubernetes.io/cpu-cpuid.FMA3=true,feature.node.kubernetes.io/cpu-cpuid.HLE=true,feature.node.kubernetes.io/cpu-cpuid.IBPB=true,feature.node.kubernetes.io/cpu-cpuid.MPX=true,feature.node.kubernetes.io/cpu-cpuid.RTM=true,feature.node.kubernetes.io/cpu-cpuid.STIBP=true,feature.node.kubernetes.io/kernel-selinux.enabled=true,feature.node.kubernetes.io/kernel-version.full=4.18.0-147.3.1.el8_1.x86_64,feature.node.kubernetes.io/kernel-version.major=4,feature.node.kubernetes.io/kernel-version.minor=18,feature.node.kubernetes.io/kernel-version.revision=0,feature.node.kubernetes.io/pci-1013.present=true,feature.node.kubernetes.io/pci-1af4.present=true,feature.node.kubernetes.io/system-os_release.ID=rhcos,feature.node.kubernetes.io/system-os_release.VERSION_ID.major=4,feature.node.kubernetes.io/system-os_release.VERSION_ID.minor=3,feature.node.kubernetes.io/system-os_release.VERSION_ID=4.3,kubernetes.io/arch=amd64,kubernetes.io/hostname=perflab-f8n55-worker-5wk49,kubernetes.io/os=linux,node-role.kubernetes.io/worker=,node.openshift.io/os_id=rhcos
Add one CPU worker:
[stack@perflab-director ~]$ oc scale --replicas=4 machineset perflab-f8n55-worker -n openshift-machine-api
machineset.machine.openshift.io/perflab-f8n55-worker scaled
Check the status:
[stack@perflab-director ~]$ oc get machinesets -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
perflab-f8n55-worker 4 4 3 3 17d
perflab-f8n55-worker-gpu 1 1 1 1 17d
One new worker CPU worker node ‘perflab-f8n55-worker-cmkh7’ is available after 5mn:
(overcloud) [stack@perflab-director ~]$ oc get nodes
NAME STATUS ROLES AGE VERSION
perflab-f8n55-master-0 Ready master 17d v1.16.2
perflab-f8n55-master-1 Ready master 17d v1.16.2
perflab-f8n55-master-2 Ready master 17d v1.16.2
perflab-f8n55-worker-5wk49 Ready worker 17d v1.16.2
perflab-f8n55-worker-bt9qk Ready worker 17d v1.16.2
perflab-f8n55-worker-cmkh7 Ready worker 47s v1.16.2
perflab-f8n55-worker-gpu-jbx27 Ready worker 17d v1.16.2
perflab-f8n55-worker-hpfcl Ready worker 17d v1.16.2
Appendix
TLS error
If you hit this type of errors:
[stack@perflab-director openshift]$ oc logs tensorflow-benchmarks-cpu
Error from server: Get https://10.0.0.28:10250/containerLogs/default/tensorflow-benchmarks-cpu/cudnn: remote error: tls: internal error
[stack@perflab-director ~]$ oc rsh tensorflow-benchmarks-cpu
Error from server: error dialing backend: remote error: tls: internal error
You can have some pendings certificates because of this bug https://bugzilla.redhat.com/show_bug.cgi?id=1737611:
[stack@perflab-director ~]$ oc get csr
NAME AGE REQUESTOR CONDITION
csr-24wv9 10h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-26nh8 14h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-2fpj2 16h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-2lg6w 4h44m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-2lmh6 145m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-4bw2j 8h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-5bvdx 23h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-66sdr 22h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-6ns8s 8h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-72rcq 10h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-75mqt 114m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-7m7m9 11h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-7xxw6 9h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-86dsj 67m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-8h9h2 3h27m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-8kr25 15h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-8lmfd 14h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-9298r 18h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-9jgg2 20h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-9mcnk 5h15m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-bctc7 15h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-bgdfp 15h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-brxl2 3h11m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-cdph5 18h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-ckw5k 129m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-dhsmb 16h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-dkkjt 13h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-f5tbk 21h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-fgb4g 23h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-fncxd 7h50m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-fqgll 9h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-fqv6r 22h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-gbxn7 15h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-gdxbl 22h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-gj98w 24h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-gjn7j 98m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-h2xtp 19h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-h72q4 37m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-hmxcl 6h48m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-j6mww 19h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-k7sjc 12h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-kj74q 17h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-kpwvs 12h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-kwp6l 7h3m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-l89nk 20h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-lkgg7 12h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-lkkzr 7h19m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-lwgn2 176m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-m27jn 18h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-m2hbh 21m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-mx6dx 11h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-n858v 8h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-nck45 16h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-ngkzj 20h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-ph75v 5h46m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-pkpxg 23h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-pm42x 17h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-pm9fv 160m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-pm9ht 9h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-pn4fq 16h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-qgmsf 17h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-ql9tw 19h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-qqdb9 83m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-qsgwr 23h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-qx8fm 12h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-r8kmq 14h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-s4vj6 6m7s system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-sjpxt 17h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-szbm9 18h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-tff74 21h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-tkl85 22h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-tl595 11h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-tv92d 4h29m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-v4nkv 7h34m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-v6sll 3h42m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-vchx4 9h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-vgph6 11h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-w26ls 13h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-wbz4l 3h58m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-wz6pm 6h17m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-wzbk5 52m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-x8c9r 14h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-xb6sb 21h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-xc786 8h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-xq2mp 10h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-xsshb 13h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-z2l7s 4h13m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-z6nkf 5h30m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-z97f4 6h32m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-zcs5n 6h1m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-zdwmr 20h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-zf85w 10h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-znx6p 19h system:node:perflab-f8n55-worker-gpu-jbx27 Pending
csr-zrgkf 4h59m system:node:perflab-f8n55-worker-gpu-jbx27 Pending
You can approve manually the certificate to fix the issue:
[stack@perflab-director ~]$ oc get csr -oname | xargs oc adm certificate approve
certificatesigningrequest.certificates.k8s.io/csr-24wv9 approved
certificatesigningrequest.certificates.k8s.io/csr-26nh8 approved
certificatesigningrequest.certificates.k8s.io/csr-2fpj2 approved
certificatesigningrequest.certificates.k8s.io/csr-2lg6w approved
certificatesigningrequest.certificates.k8s.io/csr-2lmh6 approved
certificatesigningrequest.certificates.k8s.io/csr-4bw2j approved
certificatesigningrequest.certificates.k8s.io/csr-5bvdx approved
certificatesigningrequest.certificates.k8s.io/csr-66sdr approved
certificatesigningrequest.certificates.k8s.io/csr-6ns8s approved
certificatesigningrequest.certificates.k8s.io/csr-72rcq approved
certificatesigningrequest.certificates.k8s.io/csr-75mqt approved
certificatesigningrequest.certificates.k8s.io/csr-7m7m9 approved
certificatesigningrequest.certificates.k8s.io/csr-7xxw6 approved
certificatesigningrequest.certificates.k8s.io/csr-86dsj approved
certificatesigningrequest.certificates.k8s.io/csr-8h9h2 approved
certificatesigningrequest.certificates.k8s.io/csr-8kr25 approved
certificatesigningrequest.certificates.k8s.io/csr-8lmfd approved
certificatesigningrequest.certificates.k8s.io/csr-9298r approved
certificatesigningrequest.certificates.k8s.io/csr-9jgg2 approved
certificatesigningrequest.certificates.k8s.io/csr-9mcnk approved
certificatesigningrequest.certificates.k8s.io/csr-bctc7 approved
certificatesigningrequest.certificates.k8s.io/csr-bgdfp approved
certificatesigningrequest.certificates.k8s.io/csr-brxl2 approved
certificatesigningrequest.certificates.k8s.io/csr-cdph5 approved
certificatesigningrequest.certificates.k8s.io/csr-ckw5k approved
certificatesigningrequest.certificates.k8s.io/csr-dhsmb approved
certificatesigningrequest.certificates.k8s.io/csr-dkkjt approved
certificatesigningrequest.certificates.k8s.io/csr-f5tbk approved
certificatesigningrequest.certificates.k8s.io/csr-fgb4g approved
certificatesigningrequest.certificates.k8s.io/csr-fncxd approved
certificatesigningrequest.certificates.k8s.io/csr-fqgll approved
certificatesigningrequest.certificates.k8s.io/csr-fqv6r approved
certificatesigningrequest.certificates.k8s.io/csr-gbxn7 approved
certificatesigningrequest.certificates.k8s.io/csr-gdxbl approved
certificatesigningrequest.certificates.k8s.io/csr-gj98w approved
certificatesigningrequest.certificates.k8s.io/csr-gjn7j approved
certificatesigningrequest.certificates.k8s.io/csr-h2xtp approved
certificatesigningrequest.certificates.k8s.io/csr-h72q4 approved
certificatesigningrequest.certificates.k8s.io/csr-hmxcl approved
certificatesigningrequest.certificates.k8s.io/csr-j6mww approved
certificatesigningrequest.certificates.k8s.io/csr-k7sjc approved
certificatesigningrequest.certificates.k8s.io/csr-kj74q approved
certificatesigningrequest.certificates.k8s.io/csr-kpwvs approved
certificatesigningrequest.certificates.k8s.io/csr-kwp6l approved
certificatesigningrequest.certificates.k8s.io/csr-l89nk approved
certificatesigningrequest.certificates.k8s.io/csr-lkgg7 approved
certificatesigningrequest.certificates.k8s.io/csr-lkkzr approved
certificatesigningrequest.certificates.k8s.io/csr-lwgn2 approved
certificatesigningrequest.certificates.k8s.io/csr-m27jn approved
certificatesigningrequest.certificates.k8s.io/csr-m2hbh approved
certificatesigningrequest.certificates.k8s.io/csr-mx6dx approved
certificatesigningrequest.certificates.k8s.io/csr-n858v approved
certificatesigningrequest.certificates.k8s.io/csr-nck45 approved
certificatesigningrequest.certificates.k8s.io/csr-ngkzj approved
certificatesigningrequest.certificates.k8s.io/csr-ph75v approved
certificatesigningrequest.certificates.k8s.io/csr-pkpxg approved
certificatesigningrequest.certificates.k8s.io/csr-pm42x approved
certificatesigningrequest.certificates.k8s.io/csr-pm9fv approved
certificatesigningrequest.certificates.k8s.io/csr-pm9ht approved
certificatesigningrequest.certificates.k8s.io/csr-pn4fq approved
certificatesigningrequest.certificates.k8s.io/csr-qgmsf approved
certificatesigningrequest.certificates.k8s.io/csr-ql9tw approved
certificatesigningrequest.certificates.k8s.io/csr-qqdb9 approved
certificatesigningrequest.certificates.k8s.io/csr-qsgwr approved
certificatesigningrequest.certificates.k8s.io/csr-qx8fm approved
certificatesigningrequest.certificates.k8s.io/csr-r8kmq approved
certificatesigningrequest.certificates.k8s.io/csr-s4vj6 approved
certificatesigningrequest.certificates.k8s.io/csr-sjpxt approved
certificatesigningrequest.certificates.k8s.io/csr-szbm9 approved
certificatesigningrequest.certificates.k8s.io/csr-tff74 approved
certificatesigningrequest.certificates.k8s.io/csr-tkl85 approved
certificatesigningrequest.certificates.k8s.io/csr-tl595 approved
certificatesigningrequest.certificates.k8s.io/csr-tv92d approved
certificatesigningrequest.certificates.k8s.io/csr-v4nkv approved
certificatesigningrequest.certificates.k8s.io/csr-v6sll approved
certificatesigningrequest.certificates.k8s.io/csr-vchx4 approved
certificatesigningrequest.certificates.k8s.io/csr-vgph6 approved
certificatesigningrequest.certificates.k8s.io/csr-w26ls approved
certificatesigningrequest.certificates.k8s.io/csr-wbz4l approved
certificatesigningrequest.certificates.k8s.io/csr-wz6pm approved
certificatesigningrequest.certificates.k8s.io/csr-wzbk5 approved
certificatesigningrequest.certificates.k8s.io/csr-x8c9r approved
certificatesigningrequest.certificates.k8s.io/csr-xb6sb approved
certificatesigningrequest.certificates.k8s.io/csr-xc786 approved
certificatesigningrequest.certificates.k8s.io/csr-xq2mp approved
certificatesigningrequest.certificates.k8s.io/csr-xsshb approved
certificatesigningrequest.certificates.k8s.io/csr-z2l7s approved
certificatesigningrequest.certificates.k8s.io/csr-z6nkf approved
certificatesigningrequest.certificates.k8s.io/csr-z97f4 approved
certificatesigningrequest.certificates.k8s.io/csr-zcs5n approved
certificatesigningrequest.certificates.k8s.io/csr-zdwmr approved
certificatesigningrequest.certificates.k8s.io/csr-zf85w approved
certificatesigningrequest.certificates.k8s.io/csr-znx6p approved
certificatesigningrequest.certificates.k8s.io/csr-zrgkf approved
oc logs and rsh are fixed:
[stack@perflab-director ~]$ oc logs tensorflow-benchmarks-cpu
Cloning into 'benchmarks'...
2020-02-16 23:36:11.348824: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.1
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/compat/v2_compat.py:61: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
...
[stack@perflab-director ~]$ oc rsh tensorflow-benchmarks-cpu
root@tensorflow-benchmarks-cpu:/workspace#